March 16, 2022
Building Multi-Region Resiliency with Amazon RDS and Amazon Aurora
John Gorry, Vice President, Transaction Banking Cloud Engineering; Naga Sai Aakarshit Batchu, Vice President, Transaction Banking Cloud Engineering; Ankit Kathuria, Vice President, Transaction Banking Security Engineering
Why Multi-Region Resiliency Matters
Achieving global availability for our services in Transaction Banking (TxB) at Goldman Sachs is essential to our business and a major differentiator for our platform. We also have a responsibility to demonstrate to regulators as well as external and internal auditors that we can continue to run our business in the event of major geographical outages or major service level outages from our cloud providers.
It's tempting when thinking about complex challenges, like availability at scale, that moving to the cloud will automatically solve all of our problems. Unfortunately, this is not the case. There are a number of reasons why resiliency on a global scale is challenging, particularly for a stateful service like a relational database. We have to ensure we can failover that state without a significant service interruption, and maintain the integrity of that state to ensure business can resume after the failover event has taken place. We have to ensure that any mechanism we have for replicating state between geographical locations takes latency into account.
- Should we replicate data synchronously and pay a large performance penalty whilst we wait for global consistency? Or should we replicate asynchronously knowing that means accepting the risk that transactions at the primary may not have replicated to the secondary when disaster strikes?
- How do we ensure our state is replicated securely with the appropriate controls in place?
- How do we start taking regional application and provider components and deploying them in a global configuration?
- When we need to trigger a failover event, how do we do that? What is the impact to running applications in the primary region? In the secondary region?
- Most importantly - how do we accomplish all of this at scale in a timely manner with critical business components on the line?
In this blog post, we will outline how Transaction Banking Engineering built on native AWS-provided resiliency options by designing and building a mechanism for failing over our relational databases in a scalable and secure way between AWS regions, along with the database credentials which control application access.
Technology Components
Our database footprint spans multiple different platforms. We utilize many platforms designed for the cloud such as Amazon DynamoDB, Amazon ElastiCache, as well as other third party and SAAS platforms. We also have a significant footprint deployed on relational database platforms. There are a number of reasons for this including dependencies on third party software providers which only support certain technologies. Our relational database footprint comprises Amazon RDS Oracle as well as the PostgreSQL compatible edition of Amazon Aurora (Amazon Aurora PostgreSQL). The focus of this blog post will be our engineering efforts to take the resiliency functionality provided by these platforms and extend it to provide a complete solution that met our requirements.
We deploy all of our components using the Infrastructure as code tool Terraform, which means we have state files to manage the resources in our AWS accounts. We must ensure that the resources in our AWS account match those in our Terraform state files to ensure ongoing deployment success. When adding new regions to our deployment, we add these as separate Terraform environments, with their own pipelines and state files independent of existing regions.
Resiliency Strategy
Our primary resiliency strategy for RDS Oracle and Amazon Aurora PostgreSQL is to utilize Multi-AZ resiliency provided by AWS.
For RDS Oracle, this involves a duplicate instance and storage being created in a secondary AZ, with synchronous storage level replication keeping the secondary storage in sync. In the event of an outage on the primary (either failure or maintenance activity), a failover is automatically triggered to the secondary, and the database is brought online and DNS updated with minimal downtime, and so potentially minimal application impact. In addition, in the event the original primary is not recovered, a new secondary is automatically created asynchronously, so full resiliency is re-established a short time later.
For Amazon Aurora PostgreSQL, the storage layer is always deployed and replicated across 3 AZs, with 2 copies of the data per AZ. This gives us 6 copies of the data for redundancy. Write quorum is achieved when a write has reached 4/6 of these copies. For the compute layer, we deploy 1 writer node, and 2 reader nodes, across 3 AZs. Applications should be configured such that write connections are sent to the writer node via the read-write cluster endpoint, and read connections are sent to the reader nodes via the read-only cluster endpoint. These endpoints are provided by Amazon Aurora PostgreSQL and the read-only endpoint utilizes round-robin load balancing to split load between reader nodes. In the event of failure of a reader node, any applications connected to that node can reconnect and be routed to the remaining healthy reader node. In the event of a failover of the writer node, Amazon Aurora PostgreSQL will promote one of the reader nodes to writer, failover the writes and update Domain Name System (DNS) with minimal downtime, and so potentially minimal application impact.
This takes care of our primary availability. However, as described above, we still need a resiliency strategy for region or service outages.
For RDS Oracle, AWS launched cross-region read replicas in late 2019. In early 2020, global database support followed for Amazon Aurora PostgreSQL. These features were the initial building blocks that allowed us to deploy a read-only replica of our data in a secondary region with asynchronous replication.
This helped shape our application deployment strategy. Our applications are primarily deployed using containers on AWS Fargate. Given we now have a process for having an active primary database in one region and a read-only replica database in one or more secondary regions, we made the decision to deploy our applications in active/passive mode.
A full deployment of the application exists in the primary region with the active database. Pre-provisioning the components in the secondary region simplifies the failover process, making it less prone to outages, elevated traffic rates or capacity constraints. Due to this, we have a full deployment in the secondary region with the replica database. Only one instance of the application is active at any one time. The infrastructure cost of secondary region components is relatively low, which made us choose to optimize the reliability of the failover process.
We do not support cross-region database connectivity (i.e. an application running active in one region cannot connect to a database which is running primary in a different region).
As mentioned, the replication for cross-region read replicas and global database is asynchronous. In many failure scenarios we would stop processing transactions prior to invoking the failover, allowing all databases in the secondary region to sync up with their primaries. There is, however, always the potential for data loss in the event of a failure, and this cannot be ignored. Our primary focus with this design was on availability, rather than durability. Thus, our focus during a failover is on reestablishing our business-critical components and being able to process new requests. Transactions which were in-flight at the time of the failover may require manual intervention to be completed in the secondary region.
The challenge was to build a mechanism for multi-region RDS Oracle/Amazon Aurora PostgreSQL resiliency that met the following criteria:
- No reliance on any service or infrastructure running in the original primary region, in case of a complete regional outage.
- No reliance on any Infrastructure as Code tools. It should be possible to failover a database without updating and deploying new code versions.
- Ability to re-establish resiliency post-failover to the original primary region without this step becoming a hard dependency, again in case of complete regional outage.
- As minimal impact on the application as possible as a result of failover. The application should not have to redeploy or reconfigure as a result of the failover action.
- Must be able to scale such that multiple databases can be failed over simultaneously.
- Must maintain the highest levels of security standards at all stages (Encryption at rest, TLS, credential management, etc).
Multi-Region RDS Oracle/Amazon Aurora PostgreSQL Failover Orchestration
Challenges
There were significant challenges we had to solve when building this solution. Some of the main ones included:
- Native AWS service features: For example, at the time of design, neither RDS Oracle or Amazon Aurora PostgreSQL supported re-establishing resiliency to the original primary region using the old primary database. Instead, a brand new replica database had to be created by the orchestration engine. Since this was a new database resource not created via Terraform, the process needed to know what configuration variables to set on the new database.
- Complexity of RDS Oracle/Amazon Aurora PostgreSQL replica management: For example, RDS Oracle replica database option group configuration was not possible via Terraform. Instead, AWS allocates system generated resources to manage replica databases. This means our failover orchestration must be aware of these system generated resources, and remove them as necessary when a replica database is promoted to a primary database, and synchronize the configuration options appropriately.
- Terraform state vs AWS state: As mentioned, the failover orchestration process has to make significant changes to the AWS state, such as changing database roles from replica to primary, and even creating new database resources. This means that after a failover exercise, our Terraform state and AWS state differ, sometimes significantly. This disparity has to be remediated.
- Failover duration: Lambdas have a maximum runtime of 15 minutes. Given the complex nature of failovers, any individual execution may require longer than 15 minutes to complete.
- Downstream dependencies: Once a failover is executed, how do we track the progress? How do downstream applications know that a failover has completed and their replica read-only database is now available as a read-write primary?
Solution
In addition to the databases, the basic building blocks of our RDS Oracle/Amazon Aurora PostgreSQL failover orchestration engine are:
- AWS Systems Manager Automation- Triggered by a maker/checker request process, this initiates the failover process.
- AWS Lambda- The main failover orchestration engine.
- AWS Systems Manager Parameter Store- Stores database specific configuration details required by the failover lambda.
- Amazon Route53- Provides the application with a regional specific DB endpoint, allowing us to update the database instance in that region during failover without the application having to update its configuration.
- AWS Secrets Manager- To store database credentials. More details later in this post.
- AWS Simple Notification Service (SNS)- To publish failover events that downstream systems can take action on.
- AWS CloudWatch- To publish failover process metrics and allow mission control and application teams to monitor failover progress across multiple databases.
Within our Terraform projects, we use a black/red deployment model to deploy a second database (red) alongside the existing database (black) in each region. However, whilst we create all the resources the red database requires, (e.g. AWS Key Management Service (KMS) key, Secrets, etc) we do not create the database itself. The database will be later created during the failover orchestration process. For each of these databases, we store all configuration information in AWS Systems Manager Parameter Store, so the failover process can get all the information it needs to carry out the failover steps.
We have created a lambda which breaks down the entire failover process into two steps. Step 1 promotes the replica database to be read write, and Step 2 re-establishes resiliency by creating a new replica in the original primary region. These steps can be triggered together as a single action or individually. In the case that the primary region has a hard outage, it's possible to do the promotion step only, and run the re-establish at a later time when the original primary region is available again.
In order to deal with the physical database in a particular region switching between black and red during a failover lifecycle, we deploy a region specific Route53 Canonical Name (CNAME) for each database set. The failover lambda updates this CNAME so that the application will always connect to the correct regional database, regardless of what step in the failover we are in.
To deal with the 15-minute lambda execution limit, we came up with an intelligent lambda recursion logic through which we are able to validate the state of the databases after every API call we make and then proceed with the next steps accordingly.
The lambda publishes failover events to an SNS topic in each account, and the application team can subscribe to those events and take necessary action (e.g. restart their tasks) after a failover has taken place.
The lambda publishes metrics for each step in the process to CloudWatch, so we can monitor the progress of each failover activity.
The failover execution flow can best be demonstrated by going through an example.
Example
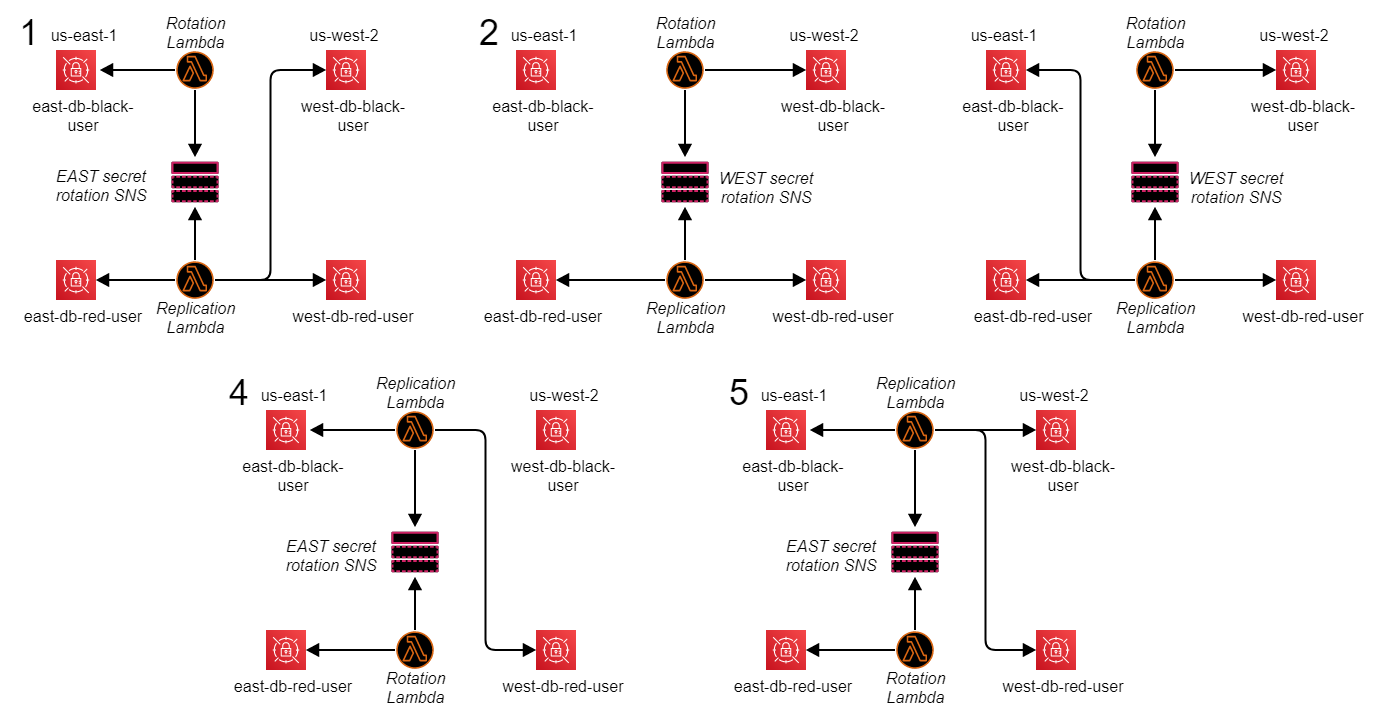
We can follow the lifecycle of a multi-region failover and failback example by examining five states:
State 1: We have a primary (master) database east-db-black in a region us-east-1, replicating to a replica database west-db-black. As previously mentioned we have deployed the necessary infrastructure for red databases in both east and west, but these do not currently exist.
At this point, we trigger the complete multi-region failover process.
State 2: We have now promoted the west-db-black replica database to be primary, and the failover lambda has re-established replication back to the us-east-1 region by creating the east-db-red database as a replica database. The lambda looked up AWS Systems Manager Parameter Store in order to know how to configure the east-red-db when it was being built. The old primary database east-db-black still exists, however, it is no longer part of the replication flow; it exists in case it's required for later data reconciliation or checkouts. At this point, the us-east-1 region Route53 CNAME has been updated to point to east-db-red, so the application is always connecting to the correct active database in us-east-1.
At this point we are fully resilient across regions once again.
State 3: We have now removed the east-db-black database since it is no longer required.
At this point, we trigger the complete multi-region failback process.
State 4: We have now promoted the east-db-red replica database to be primary, and the failover lambda has re-established replication back to the us-west-2 region by creating the west-db-red database as a replica database. Just as in State 2, the failover lambda used AWS Systems Manager Parameter Store and Route53 to configure the new replica database and update the us-west-2 CNAME so the application is connecting to the correct active database in us-west-2. At this point, we are fully resilient across regions once again.
State 5: We have now removed the west-db-black database since it is no longer required, and now we are in the same resilience setup as when we started.

Once the failover process is complete, we do require the application to make a small number of changes to their Terraform projects. Currently, we require the following database variables to be passed via Terraform:
- Database Role (Primary (Master)/Replica/Stand-alone)
- Primary Database Identifier/Region (for a given replica database, the name and region of the corresponding primary database)
- Create Database (A true/false flag for whether this particular DB is currently created). For example, in State 1 above, this is true for east-db-black and west-db-black, and false for east-db-red and west-db-red. By the time we reach State 5, these are reversed.
As part of failover post-steps, the application must update these to match the updated state in AWS so that future deployments are consistent. They must also import into Terraform any database which was created during the failover process.
Multi-Region Database Credential Management
We use AWS Secrets Manager to store and manage our database credentials. Due to the way Secrets Manager currently handles database credentials there are effectively two sources of truth of any individual credential: the database itself and the corresponding secret in Secrets Manager. Changing a database credential (e.g. rotating a secret) involves ensuring that the credential is updated both in the database itself (via a change password SQL command) and the secret. Our existing secret rotation lambda currently manages this synchronization.
Adding multi-region functionality further complicates this model. Whilst the RDS Oracle/Amazon Aurora PostgreSQL credential is synchronized automatically multi-region via those services' native replication process, the same is not true for the corresponding secret. At the time we started building the failover orchestration, Secrets Manager had no multi-region capabilities. Thus, we had to build a secrets replication process for database credentials that could satisfy the following criteria:
- Must be able to differentiate between a primary secret and a replica secret
- Must be able to replicate new/updated secret data from primary secrets to replica secrets, including multi-region
- Must be able to failover a primary secret to a replica secret, and re-establish replication to the original primary region
The key challenges we had to address were:
- Due to deploying to different regions via different pipelines and Terraform state files, we had no way of defining explicit dependencies between primary and replica secrets.
- There was no way to determine if a given secret was for a database which was currently a primary or a replica.
- There was no way to determine which regions a given secret might have replicated copies in.
There are four main components of the secret replication process:
- Primary and replica secrets in AWS Secrets Manager (pre-existing)
- A secret rotation lambda (pre-existing)
- An SNS topic to publish secret rotation events (new)
- A secret replication lambda (new)
Step 1 - Secrets. We use tags to define the dependency between primary and replica secrets. A unique identifier that identifies a replica set of secrets is created, and that identifier is placed in the tags of each secret in that replica set. Another tag identifies which regions are active for the associated RDS Oracle/Amazon Aurora PostgreSQL database, and so which regions require the secret to be replicated.
Step 2 - Secret rotation lambda. We modified the existing lambda so it can determine if a secret belongs to a primary or replica database by querying the RDS API to determine the database's status. If the database this secret belongs to is a replica, the rotation lambda performs a no-op. If the database is a primary (or non-replicated) rotation proceeds as normal. We have a secret rotation lambda deployed in each region.
Step 3 - SNS topic. We added an SNS topic which the secret rotation lambda now publishes rotation events to. These events can now trigger the replication lambda. We have an SNS topic deployed in each region.
Step 4 - Secrets replication lambda. We have a secret replication lambda deployed in each region. This is triggered either via Terraform when a replicated secret is created, or when a rotation event is sent to the SNS topic. Once triggered, the secrets replication lambda performs the following steps:
- Checks if the rotated secret is eligible for replication, by checking the tags for the replica set identifier mentioned previously
- Checks all secrets in all active regions looking for the same replica set identifier
- Copies the password from the rotated secret to all other replica set secrets
Example
By stepping through the same five states as the database failover, we can view how the secret replication process works. As mentioned above we have secret rotation lambdas, secret replication lambdas and SNS topics deployed in each region, but in the diagrams below only the active ones are shown. It's important to note that we don't directly trigger secret rotations during the failover orchestration. However, if a rotation event is triggered, it's important that the rotation and replication flow work as designed regardless of which failover state we are in at the time. This flow is shown on the diagrams below.
State 1: We have a database user secret for each of our four databases. Since the east-db-black is currently primary, secret rotations are only respected for its secret. Whenever a rotation event is triggered on any of the other three secrets, this is a no-op. When a rotation does happen for the east-black-db secret, the rotation lambda writes to the regional secret rotation SNS topic. The replication lambda in the same region then runs, and replicates the updated secret value to all replica secrets in all regions.
At this point, we trigger the complete multi-region failover process.
State 2: We have now promoted the west-db-black replica database to be primary. Thus, this is the secret for which rotation events are active. Since this secret is in the us-west-2 region, any rotation event is written to the us-west-2 secret rotation SNS topic. The replication lambda then triggers and replicates the updated secret value to all replica secrets in all regions. Notice that at this point, that does not include the old primary database secret. At State 2, the old primary database (east-black-db) is not currently part of the replica set, so any database credential changes would not replicate to it. We therefore do not want to replicate secret changes at this time to ensure consistency.
State 3: We have now removed the east-db-black database since it is no longer required. At this point, we start replicating updated secret values to the east-db-black secret once again, as it will be an important part of the failover process moving forward.
At this point, we trigger the complete multi-region failback process.
State 4: We have now promoted the east-db-red replica database to be primary. Thus, this is the secret for which rotation events are active. Similar to State 2, we stop replicating secret updates to the old primary DB, west-db-black in this case.
State 5: We have now removed the west-db-black database since it is no longer required, and now we are in the same resilience setup as when we started. We have started replicating secret updates again to west-db-black and now all of our secrets are synchronized once again.
Now we have a mechanism to keep all of our secrets synchronized across multiple regions for a given replicated database. Since the lambdas query the RDS and Secrets Manager APIs in real time, regardless of which phase of a database failover event we are in, our secrets replication process always knows which secrets belong to the same replica set, and which are for primary and replica databases. Also, by knowing when databases are or are not part of the replica set, we know when the secrets need to be replicated and when they do not. This means that the credential in Secrets Manager will always match with the current value inside the database for any of the databases at any of the failover states. This process has been extremely successful in keeping our database secrets valid during multiple failover events.
Future Enhancements
Our multi-region toolset is in constant development. This post has focused on failover for RDS Oracle and Amazon Aurora PostgreSQL, however as previously mentioned we continue to grow our footprint on other database platforms such as DynamoDB, ElastiCache, and more. Appropriate multi-region tooling for these platforms is in active development. For our existing solution, we continue to focus on adding new functionality from AWS when it becomes available, as well as enhancements to the components described in this post.
New Functionality from AWS Services
We continue to work with AWS on new functionality from the various services mentioned here, to provide more native multi-region features and reduce the amount of customer engineering we have to deploy.
In 2021, AWS launched a managed failover process for Amazon Aurora PostgreSQL, which allows us to personality swap between a primary and replica cluster, without the need to build a new replica back in the original primary region. This greatly simplifies the database component of the failover process. However, it relies on both current primary and replica clusters being available at the time the failover is triggered. This works great for planned failovers, BCP tests, etc. However, it would not work in the event of a true region or regional service outage, so we still need our design for such events.
Additionally, in 2021 AWS Secrets Manager launched multi-region replication for secrets, and we are working on onboarding as much of that functionality as possible, integrating it where necessary with our existing tools.
Enhancements to Our Own Tools
We are making continuous incremental improvements to our tooling. These include, but are not limited to:
- Generating failover events via SNS topics that application teams can subscribe to in order to kick off downstream application post-failover activities.
- Generating more in depth metrics on the different failover phases.
- Adding support for automatically restarting application container tasks in the event of a database failover.
- Adding the ability to batch database failovers so that larger failover events can be managed with fewer user interactions.
- Automating certain global database configuration parameters so they are no longer managed by Terraform and so do not need to be updated by application teams post-failover.
Our aim is to continue to add stability and scalability to our processes, while at the same time reducing the overhead on our application and mission control teams.
Lessons Learned
Multi-region resiliency for stateful services like databases is a complex challenge to solve. Deploying resources in cloud environments does not automatically solve all of these challenges, but leveraging AWS services along with our own engineering has made it a manageable task. Relational database offerings from AWS such as RDS Oracle and Amazon Aurora PostgreSQL launched initial multi-region features relatively early in our multi-region journey. These focused on deploying read-only replicas in secondary regions, and whilst we could promote a read-only replica to be a standalone database, re-establishing resiliency was not an available feature, and still is not fully available for all of our use cases. For all the new features offered by native AWS services, as well as our own tooling, deploying and managing resiliency for multi-region relational databases retains ongoing complexity.
By contrast, newer non-relational databases technologies such as DynamoDB have been able to support multi-region deployment for several years. With DynamoDB, we can deploy global tables which have native bi-directional replication between multiple regions. We are also not restricted to read-only replicas as DynamoDB global tables are multi-master. This means that multi-region complexity is greatly reduced as we don't require any database specific failover tooling.
As we continue to advance our multi-region strategy, we intend to prioritize the use of these newer database platforms where appropriate, to reduce the overall complexity of our environment and take advantage of more of the provided tooling of these database platforms which have been specifically designed for cloud-native use cases such as ours.
Join Us!
We're hiring for several exciting opportunities in our group.
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.