Well-maintained applications usually have generous test coverage, spread across unit tests, integration tests and performance test suites. Despite this coverage, incidents in production can be due to unfavorable operational scenarios ranging from infrastructure and network faults to unexpected traffic patterns. Circumstances like underlying database failures, domain name resolution failures or compute node failures have resulted in high Mean Time To Detect (MTTD) and Mean Time To Recover (MTTR), thereby breaching the application’s Service Level Objectives (SLO). These incidents have highlighted the gaps in the existing test patterns, timing and verbiage of the monitoring as well as engineers’ unfamiliarity with system behavior under various operational faults. The nature of these failures are such that they cannot be covered as part of the unit, integration or performance test suites. Resilience tests are used to assert on the application’s ability to keep up with its promised SLOs in the face of incidents. This allows developers to reason about application behavior in undesirable operational scenarios in a data-driven manner, assess operational impact, evaluate mitigation strategies and execute improvements in a controlled environment.
While the resiliency test suite helps identify opportunities to improve the overall MTTD/MTTR of the application, their manual executions tend to be time consuming, one-off, infrequent exercises requiring greater effort in planning. This leads to application observability and incident runbooks being frequently outdated and makes scaling the tests across an entire application cumbersome, especially since applications evolve at a faster pace than the frequency of the test execution. Performing the execution through standard Continuous Integration and Continuous Delivery (CI/CD) pipelines enables engineers to continuously assess the resiliency of the system in Software Development Life Cycle (SDLC), thus allowing detection of resiliency gaps in a timely fashion. Executing resilience tests as part of the pipeline ensures that they can be scheduled frequently with minimal effort. Additionally, they can be used as a control gate by application developers to flag resiliency weakness introduced as part of a deployment. For this exercise, we leveraged ChaosToolkit, an open source chaos engineering tool to orchestrate the test execution, along with GitLab as the CI/CD platform. While the toolkit itself comes with built-in support for fault injection into multiple cloud provider offerings, we have also authored additional plugins for custom faults.
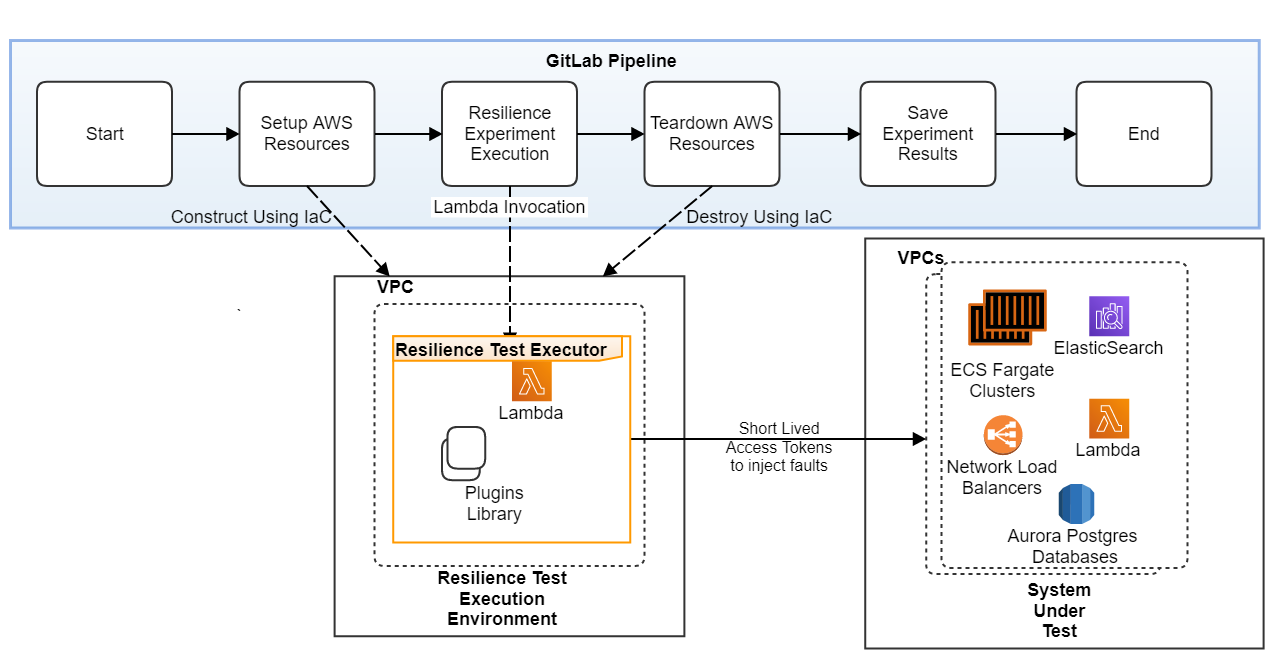
Resilience Test Suite Execution
The System Under Test (SUT) in this case is an architecture on AWS that consists of 7 micro-services spread across 5 AWS accounts and multiple Virtual Private Clouds (VPCs). The architecture entails Fargate Clusters, Aurora PostGres databases, ElasticSearch Cluster, Lambdas and Network Load Balancers apart from connectivity to external dependencies through VPC Endpoints. The application has promised Service Level Objectives (SLO) of 99.99% availability and p95 latency of 50ms.
A dedicated sandbox environment as a AWS VPC is set up for the resilience test execution. This environment is setup, torn down via Infrastructure as Code (IaC) as part of the pipeline. The resilience test execution is invoked from the pipeline and uses a short-lived access token to inject chaos into the application. The test execution environment is ephemeral, which ensures that it has elevated privileges over the SUT only for the duration of the test execution and thereby reduces the risk to the application. Failure of a test results in the failure of the pipeline. Once the experiments are executed, the results are uploaded to the test result repository by the pipeline. This also serves as an audit trail of all fault injections.
The chaos simulated in the system can be of varying blast radius and are categorized as below.
- Infrastructure Faults: Compute node failures are simulated by bringing down one or more Elastic Container Service (ECS) task instances. Underlying database failures are simulated by bringing down or failing over the database cluster. The impact of infrastructure fault can range from a small blast radius (a single compute node failure) to a much wider blast radius (an entire availability zone/region failure).
- Network Faults: The application’s VPC endpoint connectivity is tampered with to affect egress to a dependency. The system behavior can help identify if the application degrades gracefully and if there are any unintended dependencies that result in complete application failure. Network faults can be used to simulate connectivity failures to internal or external dependencies.
- User Traffic Patterns: Different user input patterns like increasing concurrent users, spiky traffic patterns, retry storms, traffic with varying payload sizes can be simulated. k6 is integrated with ChaosToolkit and can be leveraged to simulate these patterns. This helps to certify if the application is able to handle unexpected traffic patterns gracefully.
Game Days
Game days are dedicated days that involve getting a team together in a room, either virtually or in person. A scenario is chosen from a suite of pre-identified resilience tests. The specific nature of the fault is not disclosed to the team and is executed. The application is observed to see if the system behavior is as expected and when it is not, engineers debug through through the scenario to restore the application to its expected performance within the promised SLOs. If the application is identified to be not resilient to specific operational outages, these gaps can be fixed before the weaknesses impact customers. Runbooks are also updated to keep up with the application and any process gaps in incident handling are highlighted. Leveraging the resiliency test suite setup, game days were conducted for the application on AWS. While the resiliency suite execution though the CI/CD pipeline allows for continuous resiliency certification of the application, game days help engineers become better equipped to handle similar incidents in the Production environments. By conducting frequent game days, they become increasingly familiar with the application ecosystem – dependencies and resilience gaps, as well as the steps to triage issues.
Resilience Test Findings
The findings from the resilience tests and game days can be characterized into the following criteria.
- Architecture Improvements: Simulating the failure of an external dependency identified an underlying risk that would silently allow malicious traffic into the system. This prompted a review of the integration pattern between the application and the dependency that would allow the optimal exposure of the application. Infrastructure faults can help identify single points of failures in the application and if redundancy can be introduced in the application to improve this. For example, simulating database failures can highlight the need of a caching layer in the application to improve availability and latency.
- Observability, Monitoring & Capacity Enhancement: Simulating the compute node failure identified long health check probe intervals (30 seconds) leading to delayed MTTD and high error rate (0.14%). By reducing the probe interval, the error rate was reduced to 0.07%. Simulating connectivity issues from a single compute instance in the cluster resulted in an increased error rate of 10%, highlighting the need for robust and frequent health checks by the load balancer. Simulating external dependency failures highlighted the lack of robust health checks and therefore increased MTTD of the failure. By simulating varying high load patterns on the application using k6, it was identified that scale up configuration was not robust, whose improvement lead to 50% increase in cluster capacity scale up time. Monitoring should be set up at the appropriate levels of sensitivity, such that routine fluctuations in traffic throughout the day does not result in alert noise. As part of game days, with engineers handling issues, the monitoring and observability gaps of the application are easily identified. The application should have the right observability tooling to help triage issues like increased latency or failures and debug outages, thereby reducing the overall MTTR. The alarm thresholds should be set just right for improved MTTD.
- Detection of Outdated Runbook & Documentation: The external dependency fault injection highlighted that the escalation methods and contacts for an external dependency should be well documented to reduce the MTTR of the system. The steps followed to investigate, mitigate or remediate an issue have to be updated in the runbooks. Outdated runbooks significantly increase the MTTR of the application.
Summary
Chaos testing helped identify resilience gaps, iteratively measure and make improvements, improved the overall stability of the plant and made the test execution repeatable with minimal effort. Using chaos tests, the application’s ability to fulfill its SLOs was evaluated. Chaos tests also helped to identify unintended startup dependencies and single points of failure in the application. With periodic, automated, up-to-date resilience tests executed as part of game days, when faced with unexpected outages, engineers have the training to handle incidents.
Explore our careers page to learn more about exciting engineering opportunities at Goldman Sachs.
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.