The Global Investment Research (GIR) Engineering Team enables Research Analysts to author, publish, and distribute research content to institutional and certain other firm clients through GIR’s Research Portal. GIR publishes original research content hundreds of times a day, with publications providing fundamental analysis and insights on companies, industries, economies, and financial instruments for clients in the equity, fixed income, currency, and commodities markets. Our goal is to provide the best experience for clients across email, mobile, on our Research Portal, and through our Research APIs.
GIR editors manually curate website pages and rank reports to highlight the best new content for broad client segments, such as European equity clients, or on a specific topic, such as cryptocurrency. However, it is impossible to manually curate the combination of interests relevant to each client. This forces clients to either attempt to create and maintain their own set of filters or to potentially miss content that is relevant to them amid the constant flow of new material.
To address the need for personalization that scales and adjusts as client interests change, we have leveraged the power of Machine Learning (ML). ML allows us to comb through billions of points of data to provide a level of personalization at an individual level that would never be possible with human curation. Based on a combination of client identified interests, client usage, and the metadata and content of our publications, we are able to suggest recommendations of reports clients might otherwise have missed and to suggest additional topics they might wish to follow. With this ability, we are able to create the best possible experience for each client.
ML has enabled us to release three significant features on the Research Portal over the past year: Recommended Reports, Related Reading, and Recommended Follows.
Recommended Reports
Problem: One of the main purposes of any content site’s homepage is to showcase the most notable new pieces of content. Editorial curation ranks and organizes the material to sort the signal from the noise, but manual curation can only go so far. A currency trader based in the UK will have a different interpretation of “most notable” than an equity investor in Japan.
To combine curation with the specific interests of each client, we placed a component of recommended content powered by our ML model on our homepage, as well as other key parts of the Research Portal. This ensures that content which may be of particular relevance to the client is exposed side by side with the content selected by editors and trending among the wider audience.
Clients of GIR have access to a wealth of content covering a huge number of companies, industries, economies, and financial instruments. Depending on their area of focus and investment strategy, many clients have specific areas of interest. As GIR’s range of content expands to cover an increasingly diverse client base, it is important that we continue to connect clients to content they value. Our Recommended Reading model enables us to highlight impactful content personalized to an individual client.
We use supervised learning to automatically recommend reports to our clients using prior readership and document metadata as inputs.
To build Recommended Reports, historical readership information is transformed into vectors representing readership patterns and relevant document features based on metadata we store for every report. This information is incorporated into a supervised learning model. For Recommended Reports, we use the XGBoost model, a decision tree-based ensemble Machine Learning algorithm that uses a gradient boosting framework.
To train and deploy this model, we leverage a number of AWS Services, most notably:
- Amazon SageMaker is a managed service for preparing, building, training, and deploying machine learning models.
- AWS Lambda provides serverless compute, enabling functions to be run without provisioning or managing servers.
- AWS Step Functions is a workflow service for orchestrating and automating processes.
In our architecture, an AWS Lambda function generates a machine learning training workflow as an AWS Step Functions state machine. An Amazon CloudWatch alarm triggers this step function on a regular basis to retrain the model using new data, and expose the newly trained model through our API Endpoint.
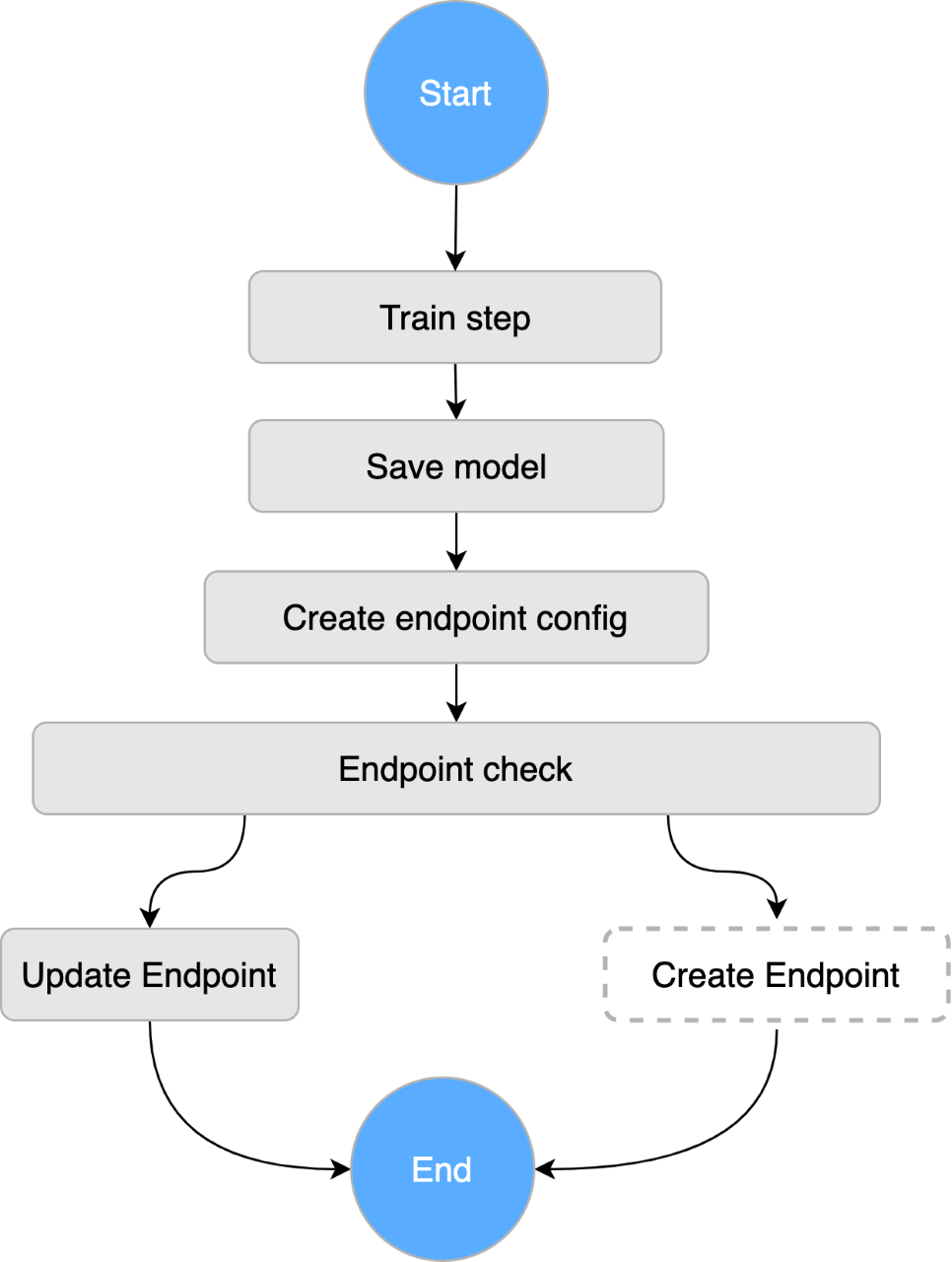
In this Step Function workflow:
- We fetch training data from Snowflake, our data warehouse, and store it in an AWS S3 bucket.
- We trigger the training job which reads training data, performs data preprocessing and feature engineering before training the XGBoost model.
- Once the model is trained successfully, it is saved to SageMaker, which provides an inference endpoint invoked by our component on page load.
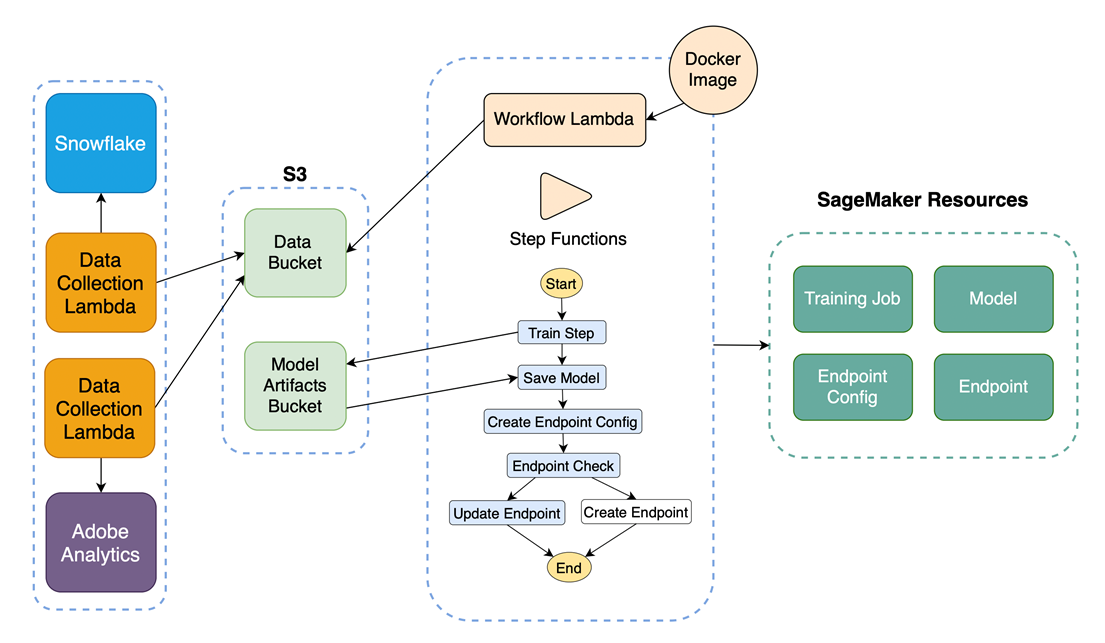
The following diagram illustrates our end-to-end architecture in AWS:
Measuring success: We measured the click-through rate of the recommended reports component powered by our ML via our model, comparing it to click-through rate of components placed in similar places on our pages.
Related Reading
Problem: After reading a report, clients have no obvious next step in their user journey despite having access to years of historical research. Research Portal clients often access content directly through email and push notifications, where this limited user journey is particularly apparent. Editors curate relevant content links alongside a number of high-traffic reports, but this cannot be scaled to cover every report.
To more broadly enhance our user journey, we built a Related Reading component, which uses ML to identify and surface related content amongst the several hundred thousands of reports available on the Research Portal.
Our Related Reading component is powered by ensemble learning, consisting of collaborative filtering (CF) and universal sentence encoder (USE) models.
CF makes automatic predictions based on users' historical readership and allowed us to make use of behavioral patterns to suggest related content.
Meanwhile, the USE model is pre-trained on a large corpus and converts documents into vector embeddings. The USE model determines document similarity based on the content of reports, where we generate vector embeddings and compute vector similarities across all available documents. USE offsets the cold-start problem where a newly published document would otherwise not be suggested soon enough for reading.
Two Step Function workflows orchestrate our ensemble model:
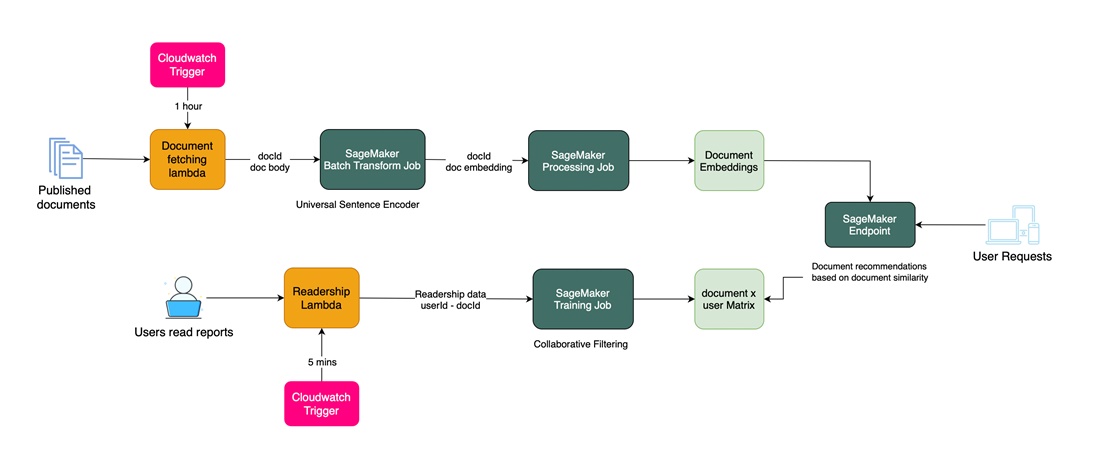
1. A SageMaker batch transform job generates USE embedding vectors for newly published documents by the hour. Then, a processing job constructs a document - embeddings matrix to enable fast similarity computations at runtime.
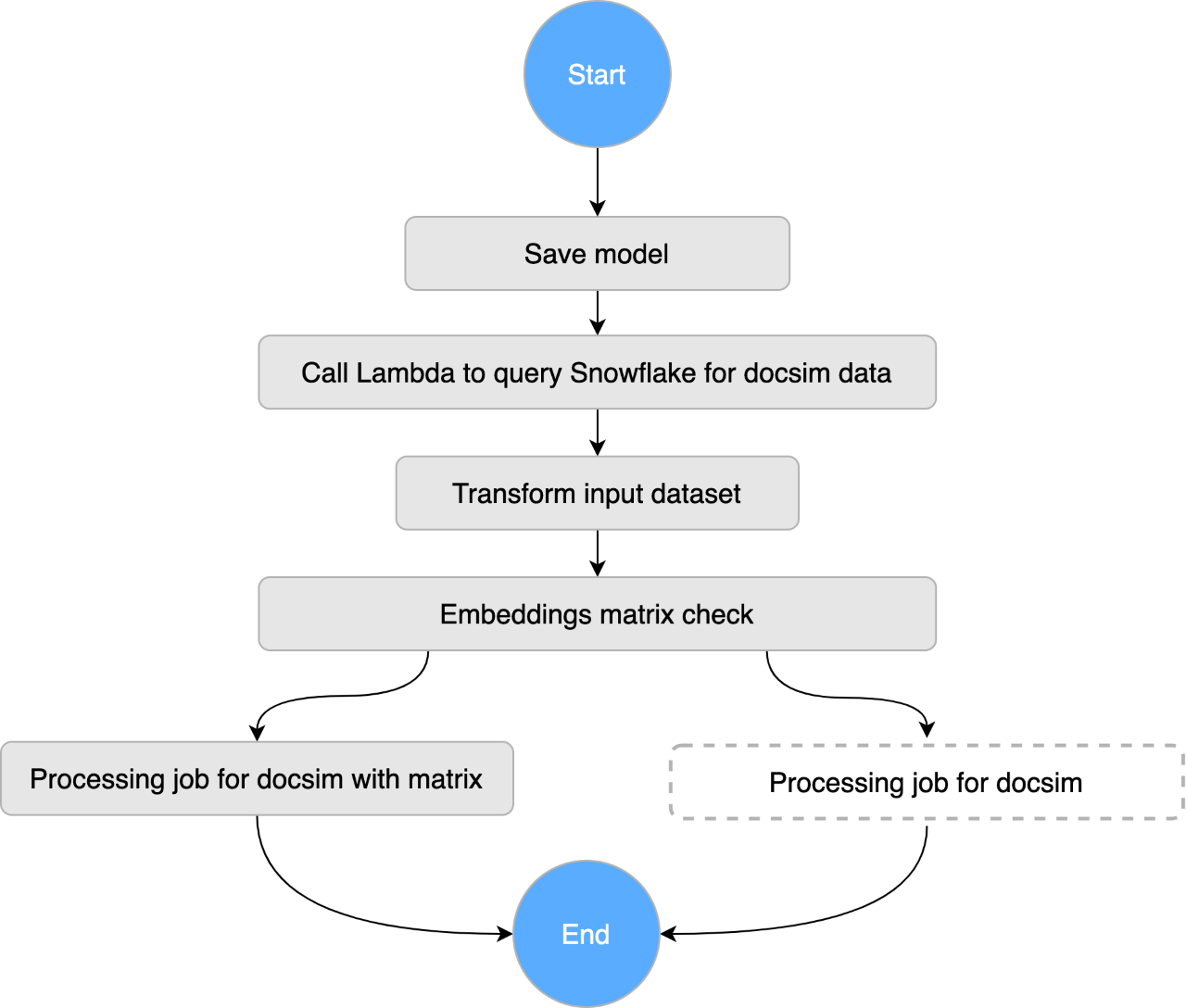
2. Meanwhile, for fast CF, we used the combination of an AWS Lambda and SageMaker training job to pull our readership stats more frequently and construct and apply singular value decomposition to a document - user matrix.
The combination of both techniques enables us to serve fresh and relevant related readings for a user on a specific report, and we combined the results of both at runtime using a SageMaker inference endpoint.
The detailed component architecture of the solution is presented in the following diagram:
Measuring success: where relevant, we measure click-through rate for the Related Reading component powered by our ML model against manually crafted components curated by our global team of curators. We also measured the length of user journey over time.
Recommended Follows
Problem: A popular feature of the Research Portal is the ability to follow authors, publications, companies, and more. With more than 1000 authors, and reports covering over 3500 companies and 450 different industries, it's challenging for clients to identify additional content they should follow and for which they want to be notified of new publications.
To surface relevant tags to the clients and improve client engagement through follows, we built a personalized follow recommendation engine.
We train a collaborative filtering (CF) model for this use case. Using a trained Collaborative Filtering model, we can recommend items that a user might like on the basis of prior interactions and identified interests. The model is retrained twice a day to surface fresh recommendations to the clients.
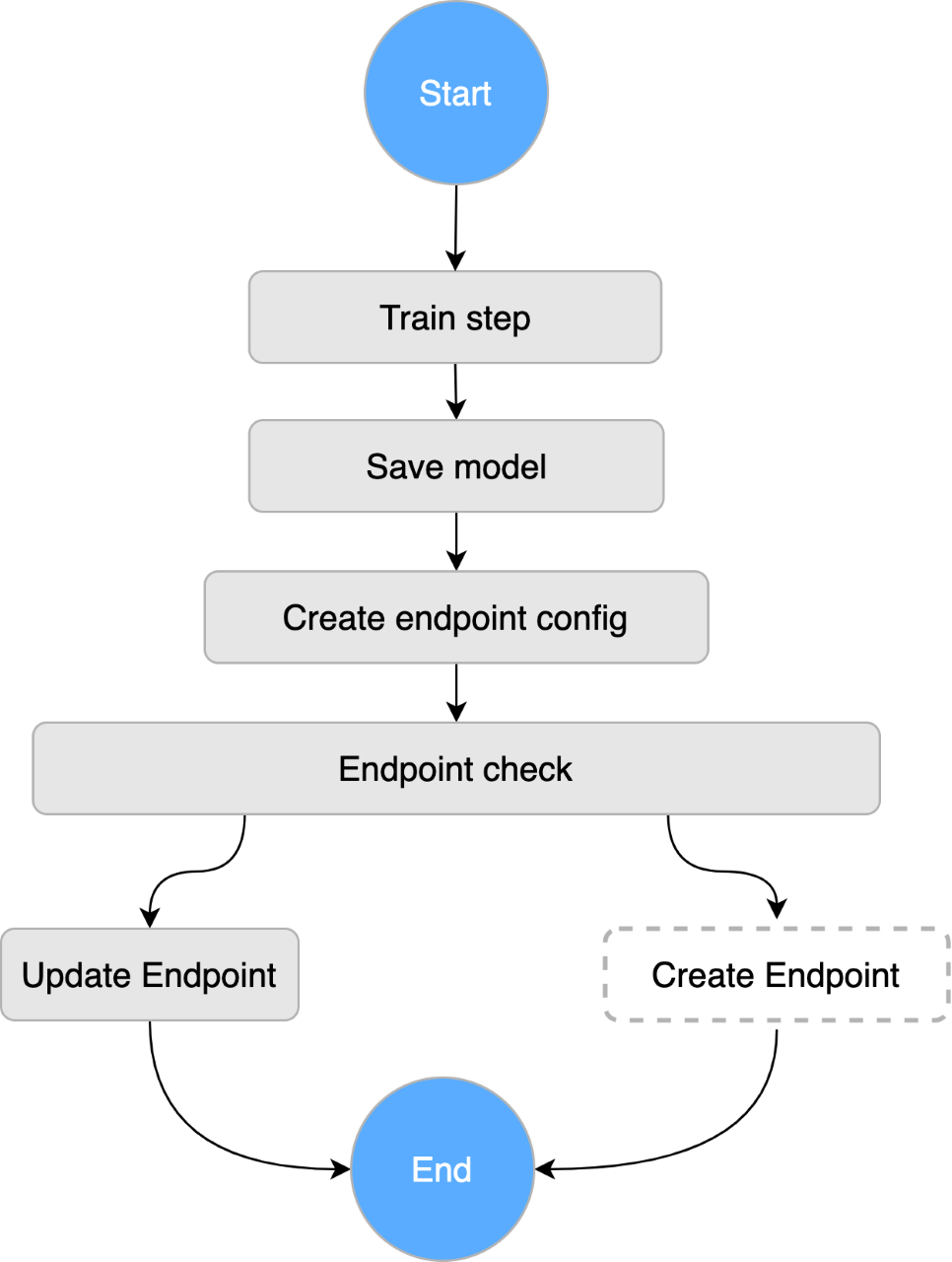
For model training and deployment, we follow the same architecture as mentioned above in the report recommendations use case.
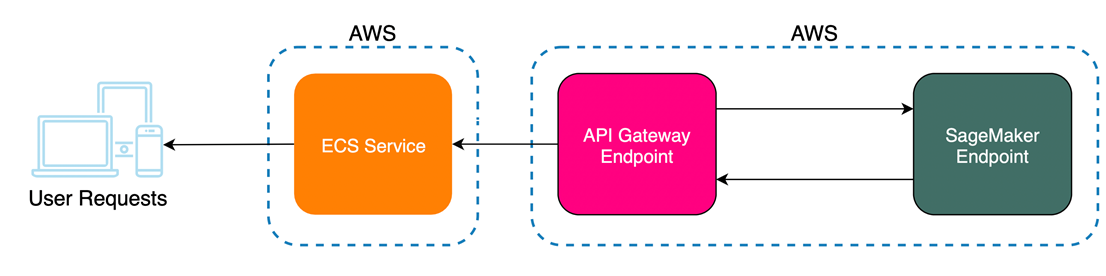
Here is a simplified diagram that shows the flow of a user request to our SageMaker endpoint; requests are made to a client application hosted by ECS, which makes a call directly to the API Gateway fronting the SageMaker endpoint:
Measuring Success: we measure individual follows and unfollows within our Recommended Follows component.
Challenges building GIR's Machine Learning Capabilities
Our team of developers was ambitious in that we wanted to do ML fast whilst also creating a reusable blueprint for future models.
Automating Machine Learning Pipelines
Amazon SageMaker helped us a lot with the infrastructure heavy lifting; however, we still had to ensure our data pipelines and machine learning jobs are resilient and secure.
As the first team using SageMaker in Goldman Sachs, we spent hours setting up resources using Terraform. We had to set up our VPC and IAM roles appropriately to ensure connectivity to our Snowflake data warehouse, and unlock access to all the offerings and integrations AWS, and specifically, Amazon SageMaker had to offer.
We use a Python Lambda with the AWS Data Science Step Function SDK to create SageMaker resources from training to inference. This blueprint has allowed us to stand up subsequent models consistently and quickly. CloudWatch triggers fetch data from Snowflake and Adobe Analytics at a regular cadence, which then becomes available to all of our models. We also trigger automated retraining using CloudWatch alarms.
When working on a new model, we follow this SDLC architecture with some additional steps if required.
Performance
The use cases for our recommendation engine directly impact the Research Portal client experience. Therefore, we needed highly performant and reliable endpoints.
The first few iterations of our recommended reports model were painfully slow - recommendation responses took on average 8 seconds. With load tests, our endpoint latency spiked further, with response times reaching 60 seconds. Adding extra compute made no difference; and so we revisited every part of our model.
Through analysis, done with the help of Goldman Sachs' Core ML team, we found that our inference input data processing and feature engineering was the bottleneck. We moved our feature engineering step to application startup, pre-generating features for each document and user in bulk; this pre-calculation removed the bottleneck. By prioritizing real-time inference latency over startup time, we massively reduced our response times from ~8 seconds to a cool sub-100ms.
Conclusion
Machine Learning plays an increasingly important role in connecting GS clients to valuable and relevant Research insights. We are able to deliver dynamic, personalized experiences based on a combination of user interests and readership. Recommended Reports and Follows are prominent across our homepage and are constantly surfacing engaging, fresh content to clients. Related Links ensures our clients can get the most value out of each piece of content available on the Research Portal.
We are continuing to build on these foundations, extending our recommendations to cover content outside of Research and integrating into more of the firm's client facing divisional portals. Augmented by a worldwide editorial team, our Recommendations features help us ensure that clients get the best experience whether through push notifications, emails or directly on the homepage of the Research Portal.
Join Us
We're hiring for several exciting opportunities! Click here for more information.
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.