Background
Early in 2020, one of our network equipment vendors announced a series of vulnerabilities that, if exploited, could have impacted our network infrastructure. We immediately made plans to deploy the vendor-provided patches to secure our infrastructure. Some infrastructure didn't support patching though, so we needed to expedite the certification and deployment of a new network operating system (NOS) version on several thousand switches and routers.
Then, COVID hit. We were still expediting the process to upgrade our network infrastructure, and, like most other companies at the time, our office buildings were empty. This enabled us to schedule NOS upgrades across several thousand devices in these buildings in a single weekend without causing user impact. Once we finished with user spaces, we proceeded to upgrade data center and network core environments, again, without causing user impact.
Many server and desktop operating systems have built-in patching mechanisms. For example, Linux has yum/dnf/apt; Windows has Windows Update. Proprietary operating systems that run on network devices mostly use older methods - copy a file to the device and manually execute upgrade commands. The file that gets copied to the device is usually a complete NOS image, meaning that deploying patches and upgrading the entire NOS are handled in the same fashion. We built a NOS upgrade system several years ago partially to respond to vulnerabilities, but primarily to ease the operational burden of manually executing NOS upgrades. We used this system to execute the aforementioned thousands of upgrades in a compressed period of time.
This post describes our homegrown NOS upgrade system, including the mechanisms we use to execute upgrades at scale in a non-disruptive fashion in both people and data center spaces.
Catalog and Inventory
Network devices in our environment are all configured in accordance with predefined patterns. We call these patterns products, each of which consists of a use case, physical hardware model, NOS version, and collection of relevant attributes. For example, we may have a product for data center access switches and a separate product for data center core routers. Each product has one or more hardware models and NOS versions associated to it. We may reuse hardware models and NOS versions by associating them to different products in a variety of permutations.
This product catalog concept mirrors the way a customer might order an item from an online store. The customer browses the catalog, finds something they like, and asks the store owner to send them one of that item. A different customer can order the same product from the catalog, and they will receive an identical but physically different item than the first customer received. In our case, a network operator "orders" a particular product from our catalog and the individual instance of that product, a specific network device, is tracked in our inventory. Since the network device maintains its relationship to a product in the catalog, we can make assertions about the new device before making it available for use by our clients. One such assertion is that the device is running a currently recommended NOS version. When it comes time to upgrade this device to a new NOS version, we mark the old version for removal and clearly specify which new NOS version to upgrade to. The catalog describes a lot more about our network building blocks but we'll leave it at this for now.
Executing an Upgrade
The NOS upgrade process is fairly straightforward. Most network devices can be upgraded using the following process:
- Copy the new NOS image to the device using any copy method available - secure copy (SCP) is most commonly used.
- Calculate the checksum of the copied image and compare it to the expected checksum posted on the NOS vendor's website or in our case, from our catalog.
- Instruct the device to install the new operating system - the device will inspect the file, validate its own configuration and ability to upgrade, execute the upgrade, and reload.
Once the device has reloaded, it typically restarts its processes and reestablishes network adjacencies. At this point, we expect the NOS upgrade to be complete and the device to have automatically reintroduced itself back into the network.
Review
Since we don't like to leave things to chance, we validate that the device came back up into a known-good state before declaring the upgrade process successful. Sometimes this means making assertions about any device that undergoes the upgrade process. For example, if we just upgraded the device to a specific NOS version, we can safely assert that the device should be running that new version. Other times we compare the post-upgrade state to the pre-upgrade state. To do this, we gather a collection of interesting state information from the device, execute the upgrade, gather the same state information again, and compare the two state collections. When comparing state, we're specifically interested in things like the state of a device's physical interfaces and routing protocols. Some state differences however are not relevant to the upgrade. A common example of this is counters that record things like the number of packets that traversed an interface since the interface came up. Other differences are expected but still need to be validated. A common example of this is when a vendor changes how the device represents a particular state in a newer NOS version. We build comparison logic to compare these two dissimilar values that represent the same state for each permutation of NOS versions that we upgrade from and to.
Workflow
We built components to handle upgrade execution and checkout and tied them together into an end-to-end workflow. The workflow goes through the following steps for each device to be upgraded:
- Validate change window parameters: As a safeguard, we validate that the device we're about to upgrade is referenced in an approved change ticket and we're currently inside the change window specified in that ticket.
- Identify the upgrade path: Look through the product catalog to determine which NOS version to upgrade to, given the NOS version the device is running and product association for that device.
- Call helper services: We need to copy a new NOS image to the device to be upgraded. If we copy files from image caches that are physically closer to the device, the overall process will take less time. We built a helper service to map a device to its physical location, and map physical locations to nearby NOS cache servers. We can also stage NOS images on devices ahead of time to save some time during our maintenance windows. We have other helper services that back up device configuration and suppress alerts, and we also interact with those services at this point.
- Take pre-snapshot: We call the checkout service to take a snapshot of the interesting device state and store that snapshot for later comparison.
- Execute upgrade: This step is where we actually copy NOS images to devices if necessary (see earlier point about staging images) and execute the upgrade.
- Take post-snapshot: Once the device upgrades, reloads, and is reachable again, we take another state snapshot.
- Snapshot comparison: We compare the pre and post snapshots and look for unexpected differences. If any are found, we present these to a network operator for validation and remediation. Once the issues have been addressed, or if no issues were found, the workflow proceeds. The remaining steps are to update the inventory to indicate that the device is running a new NOS version, and to remove the alert suppression entries that we entered prior to executing the upgrade.
Detecting Conflicts
The initial version of the upgrade workflow worked well, however we knew that we could optimize the process and reduce the burden placed on our network operators during maintenance windows. We determined that an optimal experience should be for a network operator to provide a list of devices to upgrade, and our system will figure out which order to execute each change. The goal is to avoid causing any complete network connectivity outages for clients. All servers in our environment connect to the network via a pair of network interfaces. This means that we should be able to take down one switch to which a server connects and this won't cause a complete outage for that server. All of our core infrastructure connects to adjacent network tiers using multiple links so we're good there, too. If the client device connects to the network using a single network interface, we're going to end up causing an outage when we upgrade the switch to which that device connects. This configuration is only common in our office buildings for devices such as desktops and phones.
The second goal of our workflow optimization effort was to safely parallelize as many upgrades as possible. We knew from previous benchmarking that our system could handle hundreds of simultaneous upgrades. We wanted to routinely reach that number in our production environment, but only if it was safe to do so.
Topology Graph
Our networks are deliberately designed in a fully resilient fashion. We know that each tier of our network connects to devices in the adjacent tier(s) in a particular way. Based on our network design, we came up with three rules that we felt would allow our system to achieve maximum NOS upgrade parallelization in a safe fashion:
- Don't upgrade directly connected neighbors at the same time - the purpose of this rule is twofold. First, it's to address false positives in our checkout process. For example, we want to upgrade devices A and B which are physically connected to each other. We take a state snapshot and gather neighbor information for A and see that B is connected. Then we upgrade A. If we then upgrade B, it may still be reloading when we take A's post-snapshot. We'll see B missing from A's neighbor list and flag this as an exception. Shortly after the network operator starts investigating, B will finish its upgrade process and reappear as a neighbor for A.
The second purpose is to properly handle access switches at the edge of our network. If client devices are connected to two switches, those two switches are often (but not always) physically connected to each other. This rule allows us to detect such relationships and only upgrade one switch at a time. We also have a fully-managed inventory of switches that provide resilient service but are not physically connected to each other. We consult that inventory if neighbor information alone isn't sufficient to safely determine how to proceed.
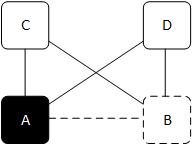
Fig 1: Device A is upgrading. We can't upgrade device B since it's physically connected to device A.
- Don't upgrade multiple devices concurrently if there is an unknown neighbor connected, or if we find a neighbor for which we don't have a complete topology - we need to make sure that devices at each network layer have resilient connectivity to devices at the layers above and below (if applicable), so if we find devices for which we have incomplete topology information, we take a very conservative approach and only upgrade its neighbors one at a time. This has the effect of forcing our entire upgrade process to only execute one upgrade at a time until we finish with the "unknown neighbor" device, but avoiding outages is a higher priority for us than upgrade velocity. These "unknown neighbor" cases are typically the result of provisioning activities that have not yet been completed.
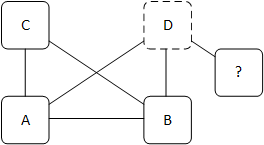
Fig 2: We can't upgrade device D in parallel with any other devices since it's connected to a device for which we don't have full topology information.
- Don't upgrade a device if doing so will take more than 50% of viable paths to a network segment out of service - in cases where two devices provide service to a network segment, upgrading one device will block the upgrade of its peer. In cases where we have multiple devices providing service to the same segment, we'll allow multiple devices to be upgraded at the same time, as long as 50% of our network capacity remains viable.
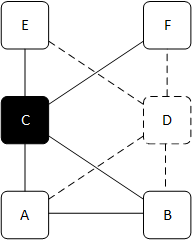
Fig 3: Device C is upgrading. We can't upgrade device D because A and B have four paths to the tier above (C, D), and two of them are already out of service. Similarly, E and F have four paths to the tier below (C, D) and two of them are already out of service.
We store network topology information in a data store and designed an algorithm, called Meath's algorithm, that uses the data store and list of devices being upgraded as its inputs. Following the three rules above, the algorithm tells us if it's safe to upgrade a device now, or if we need to wait until other upgrades finish before starting to upgrade that device.
These rules can feel somewhat abstract, so here's an example of how they work in practice. Using the topology shown in figure 4, we'll work through upgrading the switches in aggregation block one (left), and the aggregation routers in block two (right).
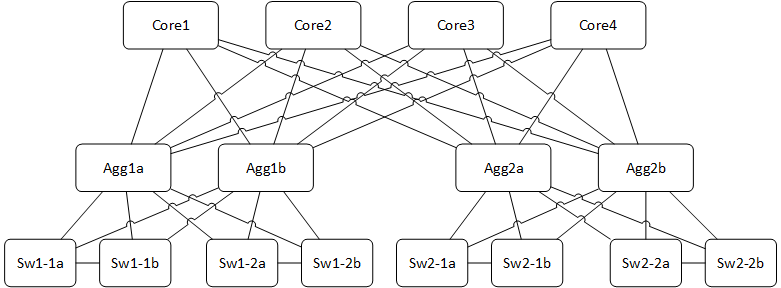
Fig 4: A busy but fairly standard network topology, consisting of four core routers, two sets of aggregation routers, and four pairs of access switches.
We start with our upgrade list, sw1-1a, sw1-1b, sw1-2a, and sw1-2b. We also add in agg2a and agg2b. We run sw1-1a through Meath's algorithm and since no devices are currently being upgraded, we start that upgrade immediately. Then we run sw1-1b through the algorithm and run afoul of rule one - a directly connected device is upgrading. We put sw1-1b back in the queue. Next, we repeat the process for sw1-2a (the upgrade starts) and sw1-2b (rule one trips us up again, so this one goes back in the queue).
Next, we work on the aggregation routers. We check to see if it's safe to upgrade agg2a - no conflicts are found, so we start that upgrade. Then we move on to agg2b. It's not directly connected to agg2a so it passes rule 1. We've got complete topology information so it passes rule 2. However, we know that there are eight links between the aggregation layer and the core layer, and between the aggregation layer and the access layer. Four of each of those links are already out of service since agg2a is upgrading. We hold off on upgrading agg2b.
After a few minutes, sw1-1a's upgrade will finish so we can reprocess the queue. We'll do so each time an upgrade is finished, ultimately upgrading the entire device list and draining the queue. In this example, we were able to automatically select two sets of three devices to safely upgrade in parallel without causing any outages for multi-homed servers in this environment. We use the same topology and algorithm in the people space. This means that devices, such as phones and desktops, connected to a single access switch (sw1* and sw2*) would experience an outage when that switch was upgraded, however the aggregation router upgrades take place in a completely transparent fashion.
Summary
We augmented our original upgrade workflow to accept a list of devices to upgrade instead of just a single device. For each device in the list, we run Meath's algorithm to determine if it's safe to upgrade. If it is, we start the upgrade and move on to the next device in the list. If we find a device that isn't safe to upgrade, we put it at the end of the list and keep processing. Once we reach the end of the original list, we wait for some upgrades to finish and then process everything again, until we've started upgrades for all devices in the list and drained the queue completely. Using this upgrade workflow, we were able to upgrade thousands of network devices in a much shorter amount of time.
We've dramatically increased our upgrade velocity, upgrading 10% of our network plant in a single change window on multiple occasions. The number of incidents and outages attributed to network issues has also been significantly reduced. Our internal clients are also more flexible when allowing us to schedule network maintenance since they rarely see impact from our network maintenance activities, further increasing our upgrade velocity.
Closing Thoughts
Automated NOS upgrades make up just one facet of how we've automated operating our network. We hope to describe our automated provisioning processes in future posts, along with some network design principles we use to build resilient networks for our clients.
Want to learn more about opportunities at Goldman Sachs? Visit our careers page.
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.