A recent engineering initiative is to provide the firm’s thousands of engineers with a portal to discover and access the technical material that they need to build new systems. The site includes step-by-step guides, conceptual explanations, reference definitions, as well as dozens of tutorials with working code samples. The site's content covers topics on, for example:
- How to produce a standardized secure Continuous Integration/Continuous Delivery (CI/CD) pipeline for your project.
- How to expose your APIs in a service architecture that mediates traffic with cross-cutting concerns such as load balancing, security, and throttling.
- How to onboard to a cloud native architecture using the firm's tooling.
The site has a rich User Interface (UI) that provides access to the latest information on the offerings the firm has, as well as a suite of Happy Paths (recipes), for accomplishing very typical scenarios that may integrate several of the firm's engineering products.
All in all, a considerable and growing amount of high value documentation is at the disposal of the firm’s engineers in this portal. Underpinning its scalability is the use of "docs-as-code", which is simply an approach whereby technical documentation is committed to version control just like regular source code. Once in version control, docs-as-code undergoes the same change control rigor that is applied to traditional code such as merge requests and code reviews. Additionally, as an artifact in a version control system, docs-as-code can take full advantage of modern continuous integration and continuous delivery (CI/CD) build technologies wherein documentation is subject to automation-based controls, such as grammatical correctness linting, a wide range of validation checks, and tests before the material is finally packaged and prepared for deployment. In our new engineering portal, all the documentation is written using Markdown, which is easily rendered as HTML in a web-based user interface. Markdown avoids the use of complex notation, which enables technical authors to focus on the content without worrying about where to place angle brackets or other syntax.
Page URLs
Now that we have a little bit of background, let's explore how this relates to the topic at hand: Managing Page URLs. The primary goal for the engineering portal is to provide our engineers with a positive user experience when accessing the material they need. We also gain the commercial benefits and efficiency savings that come from easily accessible, easy to understand, high-quality documentation, not to mention the user frustration that's avoided when the information is trusted, accurate, up-to-date, and reliable. Consistent with these overall design goals of the project, we also wanted to ensure that the site uses page addresses that meet high-quality standards. Namely, that the site's page addresses (page URLs) that expose our content are succinct, neat, meaningful, and easy to remember so that they can be easily typed into a browser, search bar, or shared with colleagues. Before we look into how we approached this, let's consider a few examples that illustrate this requirement to adopt a page address strategy that meets these goals.
These first two show the page addresses to access entry level documentation for two of the offerings provided on the site: tooling for workflow and cloud engineering platforms respectively.
Note: Links below are examples and will not result in a live page.
1. https://engineering.gs.com/workflow - overview documentation for the firm's workflow engineering tool set 2. https://engineering.gs.com/cloud - overview documentation for cloud native development
Going a level deeper, the following shows a child page of the workflow tooling and its principle getting started tutorial. Similarly, for cloud native engineering, example illustrates the symmetry and consistency of the page addresses.
3. https://engineering.gs.com/workflow/tasks/docs/getting-started - a starter tutorial for this offering 4. https://engineering.gs.com/cloud/entitlements/docs/getting-started - another starter tutorial for a different offering
This example demonstrates conceptual documentation
5. https://engineering.gs.com/workflow/tasks/docs/concepts/task-management - conceptual material is also represented through standardized URLs
A happy path 'recipe' that ties together a number of offerings into a typical user integration scenario
6. https://engineering.gs.com/happy-paths/cloud
And finally a case study for a reusable workflow product
7. https://engineering.gs.com/workflow/tasks/case-study
While simple and succinct page addresses may not be the first thing that an end user takes note of when they access a site, they do affect the overall user experience and well-chosen page addresses contribute positively to that.
Engineering for Page Addresses
The first challenge in our docs-as-code setting is that all of these pages are just plain and simple physical markdown files with their own unique filenames, which exist in the filesystem of a docs-as-code project. Herein lies the challenge. While the page address for entry level information about the toolset: https://engineering.gs.com/workflow/tasks is standardized and succinct, its actual content, its words, images, and other assets are ultimately provided by a physical file whose paths will not be perfectly aligned with the site's URLs, and nor should they be because the author should not determine the URL policy of the site. For example, a previous page address's contents might be supplied by the file: /main/resources/docs/task-engineering/markdown/tasks_overview_v1_1.md. While this physical path is organized by the author according to a directory structure that makes sense at the file system level, this deeply nested file path should not in any way be exposed as the actual page address for end users. Specifically, we do not want to leak the details about its physical storage. Instead, the page address reflects the standard convention that describes a logical and consistent taxonomy used throughout the site. The example file whose role is that of an overview needs to be resolved to the following page address:
/main/resources/docs/task-engineering/markdown/tasks_overview_v1_1.md ==> https://engineering.gs.com/workflow/tasks/
Besides creating a human-readable URL that obscures the physical location of the file, each markdown file's URL needs to reflect the product/toolset taxonomy to which it belongs. The challenge is that each markdown file is also likely to include dozens of embedded links within it to other files. In this docs-as-code approach using markdown, the markdown link convention [name](link) is used in which the (link) is defined as a relative or absolute file path to the target file. For example, an overview page may include a link to the getting started document, with a relative path to the target file.
[Getting Started](../common/tutorials/getting_started_v1_4.md)
Before the contents of the overview file is rendered as a page on the site, this relative path would need to be transformed into the page address, from which the target file will be served. For example, the embedded link is transformed as follows:
[Getting Started](../common/tutorials/getting_started_v1_4.md) ==> https://engineering.gs.com/workflow/tasks/getting-started
To add to this, documents typically also include embedded file paths to other assets such as image resources and other binary artifacts. Assets are usually packaged separately and assume a different page address convention, so the page address for assets need to adopt a different strategy for the assets/images to be displayed on the page. For example, the relative link for the image setup.png would be transformed as follows:
[Setup](../common/images/setup.png) ==> https://engineering.gs.com/static/ddffba866aefa04773fb4c1e5e3e489c/setup.png
To further demonstrate, the below example is a fragment of a markdown file that illustrates these practices. It includes three links to other files in the same file system (/images/mainHeader.PNG, ../common/tutorials/getting_started_v1_4.md, and ../common/images/setup.png), all of which need to be transformed into their respective page addresses at which the target content will be rendered. Note that this fragment also exploits the use of metadata in the form of front-matter (.yaml). This metadata helps manage a number of aspects of how the page should be visualized within the site and also to control the strategy for determining its page address. In this example we see that the role of the file is declared as overview in the metadata, so we can then apply a page address that's appropriate for an overview of a product. This metadata can be used as flags to tell the site which base address to use.
---
"@context": http://schema.org/ <=== Meta data in the form of front matter
"@type": TechArticle
name: Tasks
description: ...
keywords: ["tasks", "workflow tasks", "workflow platform", "workflow studio"]
template: productOverviewV2_0
platform: workflow
entityType: product
role: overview <=== this file has a specific role
image: /images/mainHeader.PNG <=== link reference as an absolute file path
---
## Overview
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
## Getting Started
An entry point tutorial
[Getting Started](../common/tutorials/getting_started_v1_4.md) <=== link to another file expressed as a relative link
[Setup](../common/images/setup.png) <=== Image link expressed relatively
...
elided for clarity
...
At this point, we have just looked at the mechanics of links and their transformation to URLs. However, links also need to work safely, and be scoped only to their designated environment. Consider if you have QA and production environments, then QA environment links must point to the QA environment, and production environment links must point to the production environment. We would not want the production environment referencing QA content or visa versa. In a system with thousands of links, authors cannot be guaranteed to always get the links right all of the time as they write markdown files. As an example of common authoring errors, instead of the relative link being defined correctly like this:
../../../cicd/products/features/feature_management_overview_v1_1.md
we might instead see this:
../../docs/cicd/products/features/feature_management_overview_v1_1.md
We may also see the intended absolute path missing the leading forward slash or the path or the file name is just wrong. 404 Pages, images not appearing in content, bad email addresses, and bad external links are always a cause of frustration for end users, so appropriate validation measures are a must to prevent this problem. In general, the earlier in the lifecycle of a document that these measures are applied in order to catch and eliminate bad links, the better. The strategy we employ is to validate at the point of authoring. There are some additional functional problems to solve, such as links in navigation menus, but these are just more variations of the issues discussed so far. This leads us into the next set of challenges: enterprise-grade engineering.
Enterprise-Grade Engineering
As an engineer, you will already know that production software doesn’t just need to do the right thing, but actually needs to do a whole lot more than just merely work! While a product system needs to address a number of technical considerations (such as operational, performance, scalability, security, and reliability concerns), there were three additional concerns that we wanted to address:
- Improve the authoring experience by ensuring that documentation certification errors (such as broken links or template violations) are intuitive, easy to understand, and simple to fix. To efficiently respond to an error, an author needs to easily understand what the issue is, where it is occurring, and get a clear recommendation on how to fix it.
- Provide insight into why the system did what it did, how the page address was computed, or why a specific link was transformed in such-and-such a way. This enables authors to quickly troubleshoot and resolve validation errors.
- Create a positive experience for the engineers that operate and maintain this system. Enterprise software exists for years, so we wanted to not only meet the needs of our clients but also take steps to provide a positive experience for the team that maintains the site. This is a large topic beyond the scope of this blog, so we won't discuss that here other than to suggest that part of the solution is for the software to easily and gracefully accommodate changes such as enhancements, fixes, or refactoring activities. Ideally, when we need to change something, we really just want to change one thing, test that one thing and release that one thing. In my experience, these technical properties tend not to emerge organically, but the good news is that all the challenges we have outlined are just regular computer science problems and, as with many programming problems, abstraction and composition are tools that can help us. Fortunately, there are some common elements to the problem of managing links we can take advantage of.
A markdown file on our site has a specific role such as:
- an overview page
- a happy path
- a getting started guide
- a case study
- a regular piece of technical reference documentation
- and so on.
That same markdown file probably contains embedded links to other files across the site, likely to be expressed as absolute or relative links. If expressed in relative form, the target file’s real path is a function of the calling file’s path; that is, we have to know the path of the calling file to figure out the intended absolute path of the target of the link. Absolute links expressed in markdown in a source control project are not fully absolute, but are instead expressed relative to their checkout directory root in the version control system (such as the local path of /platform/docs/common/images/setup.png, as opposed to the true absolute path from the root folder of a Linux host that might have a path of /local/home/vc/builds/mydocsascode/platform/docs/common/images/setup.png). In a sense, even absolute paths have their nuisances. A file’s true absolute path is composed of an environmental element and this, it turns out, is also an important concept when transforming file links to page addresses.
Of course, ultimately software needs to do the right thing; you can’t just wish away complexity. Fortunately, abstraction and composition helps keep a lid on accidental complexity that can creep its way in if you don’t take steps to avoid it. While this domain of link management has deep complexity, the problem possesses some strong natural concepts that reflect the underlying business truths and rules. Fortunately, these concepts and natural abstractions can easily be exploited to keep the software simple while having the desirable technical properties discussed earlier. These are captured in the domain model below. Given this software model, the problem of managing links in a file based system can be understood at a glance based on the concepts, their capabilities, and their relationships illustrated.
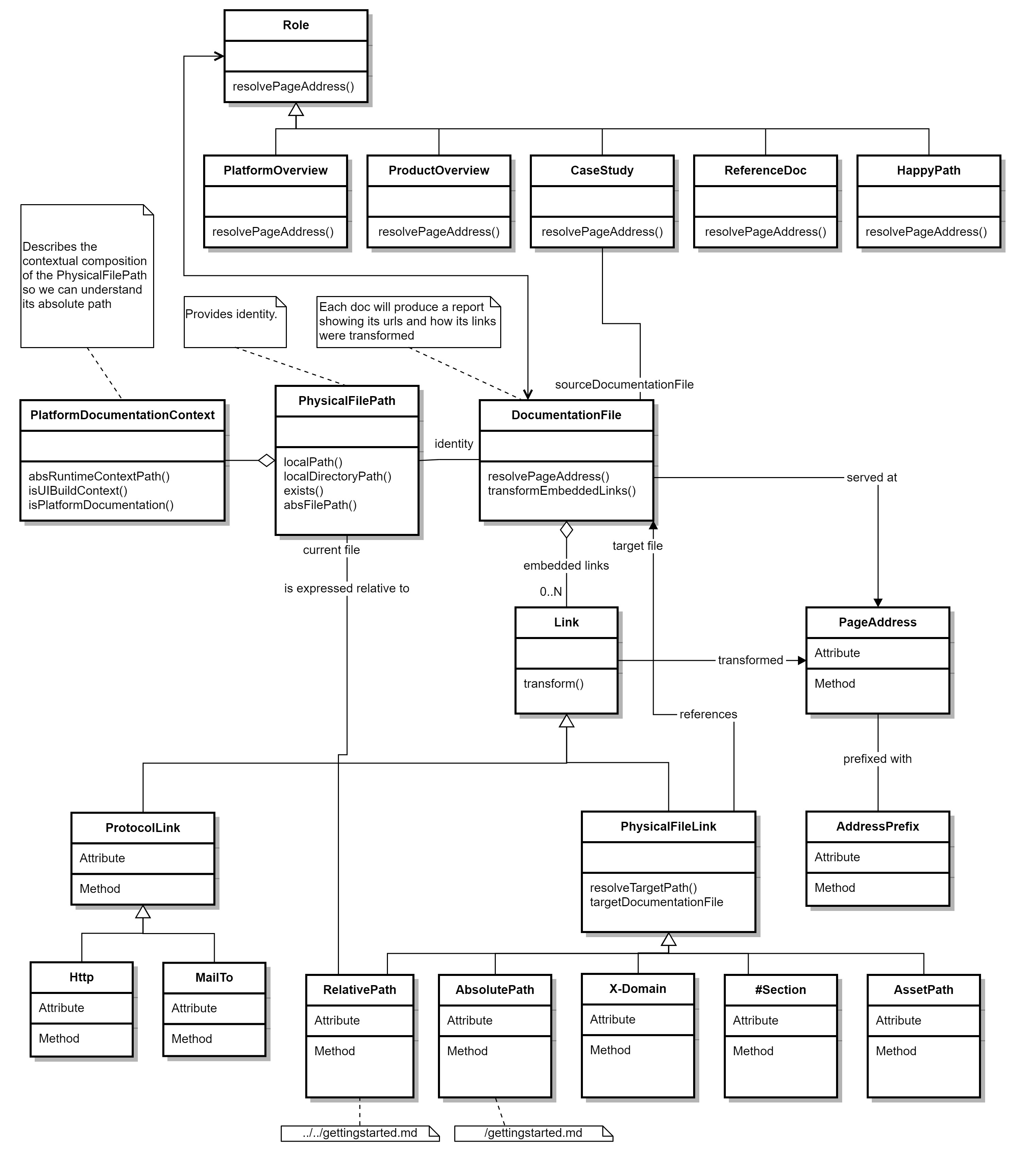
In this model, we can see the central class DocumentationFile, which represents the markdown file and is responsible for most operations. Based on our understanding, it needs to do quite a few things:
- Produce the page address at which its contents should be served. For example, https://engineering.gs.com/cicd/getting-started.
- Transform the embedded links from file system paths into the page addresses for content to which they refer.
- Ensure that these transformations are sympathetic to their runtime environment (development, QA, production, etc.).
- Validate a file and its links, and provide clear explanations if there are any issues and how to resolve them.
- Record the circumstances for how the outcome of the link transformation was arrived at so that user queries can be addressed easily.
The methods resolvePageAddress() and transformEmbeddedLinks() primarily deal with these responsibilities.
We can also see from the diagram that class DocumentationFile can have many embedded links. These can be links to absolute or relative paths to other documentation files in the filesystem, asset links, or protocol-based links. Since each embedded link needs to be transformed to the target page address, each link offers a single method—transform()—that expresses its capability to be transformed into the appropriate page address for the kind of file and the environment in which it is hosted.
We can see that the DocumentationFile has a Role (such as Overview, Case Study, Happy Path, etc.), which influences how the page address will be assigned. The PhysicalFilePath is also recognized as a first class concept which is not just as a string, but also a construct that helps reveal the composition of the runtime file path, which enables us to easily understand and separate the environmental path information from the path defined in the markdown file by the author. With a model that understands the problem of link management, we can put it to work for us in different ways:
- Figure out the page address on demand.
- Transform embedded links.
- Validate individual page addresses or even screen a whole file system for rogue links.
In addition, once the knowledge is captured by a domain we also apply it in different application runtimes, such as:
- During authoring of the files in docs-as-code projects.
- At docs-as-code build time in the CI/CD pipeline in preparation of the merge request.
- During validation during injection of the raw content into the UI.
- When building the pages for the site.
Irrespective of where, when, or how it is called we should always get the same answer.
Wrapping Up
While only a modest piece of programming, we were able to accomplish quite a bit both functionally and operationally. Although the ultimate test here was to eliminate and prevent broken links on the site, we did want to do this in a sustainable way that ticked off those technical properties mentioned earlier. In particular, to exploit the use of the link management domain to trap rogue links early on in the authoring lifecycle, to fail the docs-as-code CI/CD build if the documentation has rogue links, and also to provide the author with sufficient information to easily fix the errors.
The table below illustrates the output of the CI/CD build failure presented at commit time if link validation failures are encountered.

In all error cases the author is presented with the following useful information:
- The local path of the file containing the rogue link 'Path of File Containing Rogue Link'.
- The raw definition of the offending link 'Raw Link Definition' captured directly from the file without any processing.
- The derived local path 'Derived Local Path'. This is particularly useful for relative links because the absolute path is based on the file system location of the calling file plus the relative path given by the author. Presenting the computed local path assists the author to easily track down the error.
- Two error codes, a high level 'Outcome Code' to indicate whether or not the resource was found and a more granular 'Reason Code' to describe the nature of the issue found.
With all this information in hand, authors can identify and resolve their errors. In the cases of the three errors captured above:
- Error number 1 is an instance where the resource was not found due to a badly defined relative path that could not be resolved to an actual file. The derived (computed) local path is displayed. With this information, an author can quickly see the problem and resolve it.
- Error number 2 is slightly different. This time the outcome code reports that the resource was found. So then why is this an error? The reason code and the derived local path provide the answer. The reason code states that the file path is incorrect and indeed the path provided in the link /images/search_service.png does not refer to a file in the file system; however, the derived local path shows where a file with the same name and similar path was found after prefixing the raw link with the path of the calling file, /platform/docs. This leads to the file system path /platform/docs/images/search_service.png of the real file. Nevertheless, this is still an error because this file may not be what the author intended to use, and even if it was, the path is still incorrect and would not be resolvable by any standard tooling such as Git or IDE based tools and so should be corrected.
- Error number 3 is a badly defined absolute link and is not found due to an incorrect file path or bad filename.
By blocking errors at source, we prevent rogue links from getting into production. A similar validation approach was also used in the UI ingestion of the documentation itself so that in the event a rogue link did find its way in, we are still able to prevent broken links from getting into the production site.
As mentioned earlier, questions will arise inevitably in a production setting from authors for those edge cases you hadn't thought of, or a condition you didn't think of testing. Of course the solution is obvious: more testing, better requirements, better knowledge of the domain, better quality tests, more thorough code reviews, more automation, the list goes on. To mitigate these unknowns, our approach is to provide deep insights into why the system did what it did so we can resolve the matter quickly. So for each validation operation or transformation that produced an error or warning we also generate a detailed report that is included as one of the build artifacts. This report is easily accessible but still needs to be specifically downloaded to ensure that it is sufficiently well hidden so as not to confuse the author with these technicalities. An abbreviated exampled report is below, which provides details that an engineer can use to gain those extra insights into the system behavior. The report includes the full details of the parent file that contains the offending link including its full file path, the role of the parent file, its page address, details about the type of link discovered, its actual file path and the error descriptors, and more. This provides the facts to facilitate a quick resolution of any user queries.
{
"documentationFileReport": { <=== Details about the parent file containing a rogue link
"parentFilePath": "C:/Code/site/documentation/cicd/git/docs/getting-started.md",
"parentRole": "ReferenceDoc",
"platformRootName": "cicd",
"pageAddress": [
{
"addressPrefix": "/"
},
{
"localPath": "git/docs/getting-started"
}
],
"pageAddressString": "/git/docs/getting-started",
"failedEmbeddedLinkTransformations": [ <=== The list of bad links in the parent file
{
"linkDetails": { <=== The details of the bad link
"rawSourceLink": "/images/user-diagram.png",
"derivedAbsoluteFilePath": "C:/Code/site/documentation/cicd/git/docs/images/user-diagram.png",
"modulePath": "docs",
"fileName": "user-diagram.png",
"role": "Asset"
},
"error": [
{
"_severity": "error",
"_exceptionType": "Absolute path does not contain required parts product name or / and docs folder"
}
],
"linkType": "AbsoluteAssetLink", <=== The link's classification, which also affects behavior
"status": "ERROR",
"resourceOutcome": "RESOURCE_FOUND",
"reason": "FILE_PATH_INCORRECT"
}
]
}
}
Finally, this piece also laid the foundations that made it possible to host previews for each of the separate docs-as-code projects that individually provide the portfolios of documentation ingested into the engineering portal. With a relatively simple piece of code, we were able to solve a reasonably complex problem in a way in which the complexity of the problem is managed by the code itself without the code adding to its own complexity. Since delivery, we have already applied fixes and enhancements. With the core domain established, we were able to leverage and scale its capabilities in different applications across our estate. We hope this brief account of managing links in a docs-as-code setting has been interesting and provided insights into how we have tackled this problem.
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.