The Problem
Engineers must design, prioritize, implement, and release changes to the systems we manage. The problem we often face is impactfully and succinctly articulating these changes to our stakeholders (our clients and fellow engineers). That is, what the change is and why it is being made (the commercial benefit).
Engineers strive to explain complex concepts using concise language to make them more digestible. This conciseness becomes so engrained in our work that we get so good at explaining what we are doing in the fewest words possible; "I am upgrading a dependency", or "I am parallelizing the execution of a function" - however, in the quest for brevity, important details can easily be lost in translation, often, those providing context on why we are making particular changes. Imagine if instead of "I am upgrading a dependency", we wrote "I am updating a dependency in preparation for a Java 21 upgrade”. Or instead of "I am parallelizing the execution of a function", we wrote "I am parallelizing the execution of a function to add an additional check in the future and still operate within the function's latency SLO".
Herein lies the problem; how do we succinctly describe what we are changing, and why we are making the change. By explaining the "what” and “why” on our change requests, we would yield potential benefits that include:
- Focus on the rationale of every change resulting in a more meaningful and commercial prioritization decision.
- Engineers acquire a greater sense of accountability, purpose, and pride in the impact their contribution will entail as they understand the impact clearly (and therefore they are more vested in their contribution).
- Through clear change descriptions, closer relationships are forged between product managers and engineers (and clients with meaningful release notes)
- Change reviewers have an improved sense of what is being changed, and why - making for more impactful, less frictional change reviews, with meaningful feedback based on change context.
- A broader shared understanding across the team of what changes are being made and the prioritization process.
With all this in mind, we embarked upon an effort focused on ensuring that within our team, each change request title (bound to 300 characters) describes the what and why of the change. Through this effort of questioning each change request title, not only did we realize the benefits, but also found that change requests became more granular. We believe that the probable cause of more granular changes is - "if I can't describe the what and why of my change succinctly in a single 300-character sentence, then perhaps it's too big". When we shared our newfound approach with other teams within our organization, they had similar sentiments about the yielded benefits – which got us thinking: how could we scale this successful practice across an entire organization?
The Solution
Our solution tackled the problem in two ways:
- Through continued sharing of guidance on the benefits of the practice of ensuring that every change describes the what and why (advocation of best practice)
- The development of tooling, weaved into our software development life cycle (SDLC), to govern how change request titles are formed (enforcement of best practice)
Though we believe the most effective way of bringing about change in the way we do things is via culture (carrot as opposed to stick), we do appreciate that often practices and controls require enforcement, and in turn these enforcements can help positively influence the desired outcome.
We advocated our best practices through engaging with other teams at all levels, setting up timeboxed pilots to gather feedback, using this feedback to improve the practice, and using testimonials to help further propagate the tooling.
The enforcements came in the form of an API we developed that took as input a change request title and responds with a Boolean output indicating whether the title explained what is happening and why. With many engineers on the same page about the good practices of well-informed change request titles, we weaved the title analyzer API into our continuous integration pipelines as a control to block titles that do not adhere to the standard. This break in the continuous integration pipeline ensures that not only titles meet our standards before they can be reviewed, merged, and released, but also reinforce the positive culture.
How does the analyzer API work?
The title analyzer is written with Java and uses natural language processing (NLP) methods (sentence splitting, tokenization, and grammatical tagging) to break down the input sentence(s) and look for constructs within the sentence(s) like nouns, verbs, and conjunctions to help answer the question "does this sentence explain what is happening and why?".
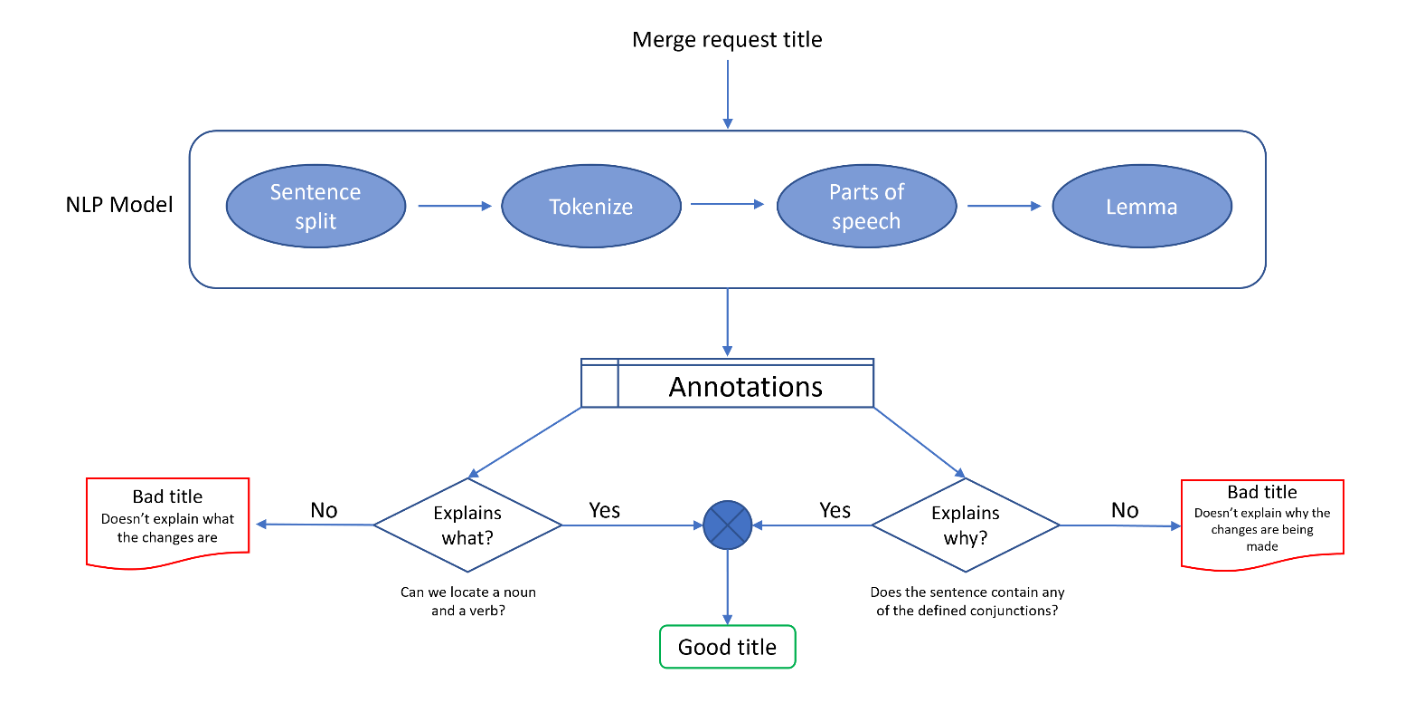
Figure 1. Merge request title analyzer overview.
When we pass a sentence to the model, it first determines if the sentence can be broken down into multiple sentences according to the punctuation. This is referred to as sentence splitting (SS) and is the entry point for our algorithm. Each sentence (if multiple) is then tokenized into single words that are further tagged (part-of-speech (POS) or grammatical tagging) using the Penn Treebank POS corpus tags to identify the type of word based on definition and context within the sentence. Finally, the tokens undergo lemmatization where each token (word) is reduced to its common root form (e.g., updated to update, issues to issue, etc.). To ascertain if a sentence contains WHAT, we locate a NOUN (i.e., dependency, Java) and VERB (i.e., updating, prepare, upgrade) in the sentence, and the WHY component is signaled through a fixed set of conjunctions (as, because, due to, in order to, since, so that, so we can, therefore, to ensure). We also have a special case where “to” can be considered a valid conjunction if the subsequent token is a VERB (i.e., to prepare). This is an example of how we have tuned the title analyzer algorithm.
Consider the following title: Updated app configuration with stop and start to avoid issues while renaming host. Added trap to ensure clean end of script.
The title is first split into separate sentences, and for each sentence, we extract annotated tokens (Figure 2) that are used to determine whether the merge request is good or bad. Taking “updated” and “app” as our example tokens, the model annotates them as verb and noun, respectively. The lemmatization process transforms “updated” into its simplest form “update” while “app” remains the same. Because the title contains a noun and a verb, we ascertain that it describes what the changes are.
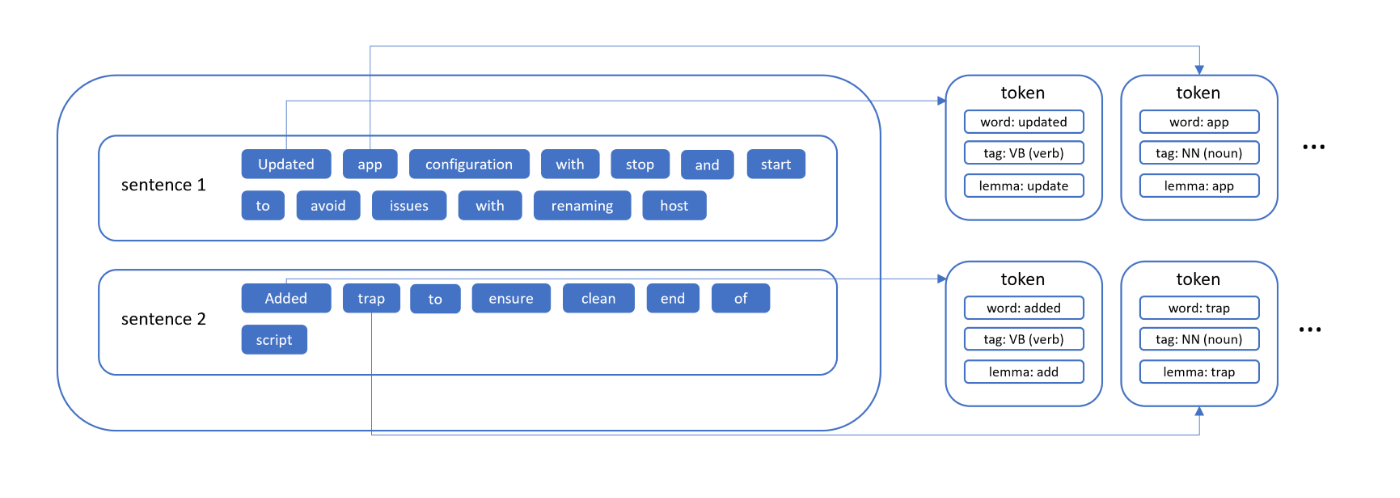
Figure 2. Parsed sections of example good merge request title.
Further, we note that the title meets the criteria of containing a conjunction in two ways. The first being the special case of the token “to” immediately followed by the verb “avoid”. The second case is the presence of “to ensure” in the latter title fragment. With this, we can confidently state that this is a good change request title.
Now consider the following title: Updated the old application QA data server instance.
This is a simpler case in which SS does not apply because we only have a single sentence. As shown in Figure 3, the sentence undergoes tokenization and lemmatization where “updated” and “application” are annotated as verb and noun, and then transformed in their base forms “update” and “application”, respectively.
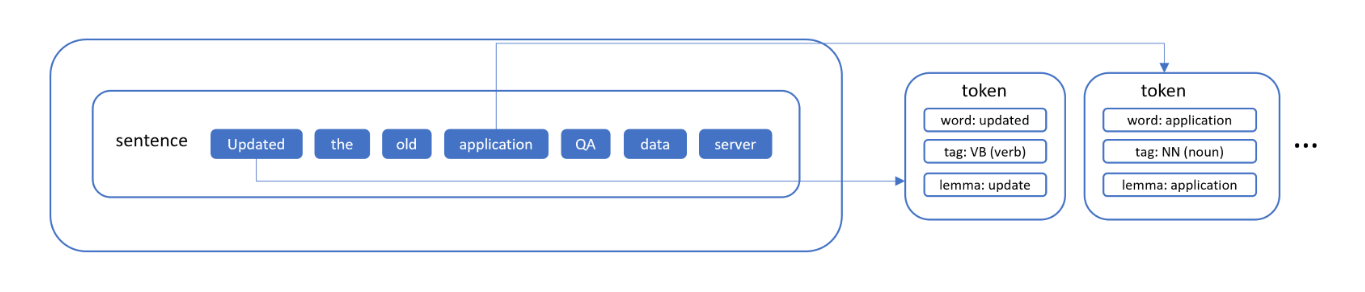
Figure 3. Parsed sections of example bad merge request titles.
Despite the title clearly indicating what the changes are, it does not contain any of the required conjunctions or qualify for the special case, hence, regarded as a bad change request title.
Performance of analyzer
Overall, the analyzer performs well with an accuracy of 93%, respectively. This evaluation is based on 3443 change request titles that we collected from our organization. We use this metric as a reference whenever we tune the algorithm, ensuring that we either increase or maintain the accuracy.
What makes the analyzer special?
The simplicity of the analyzer offers the following benefits.
- Transparency: Because we have simplified the analysis process, it becomes easier for engineers to understand the decision-making process. Everyone can easily grasp the criteria used to evaluate change request title quality, facilitating learning, and driving improvement overtime.
- Cost-effective: The analyzer only requires a fraction of standard computing to run, which enables us to leverage our existing resources with no additional investment. In addition, the algorithm is simple with only a few dependencies resulting in limited maintenance cost. While there is some upfront investment required at the integration stage, the long-term return on investment is substantial.
- Ease of integration: As highlighted earlier, we integrated the analyzer into our SDLC as a control that breaks build pipelines if the change request title is not acceptable. This was a straightforward process that required minimal dependencies and configurations making adoption straightforward for other teams. The ease of integration ensures that the analyzer becomes an integral part of the development process with minimal disruption.
The Outcome
After introducing this control within an organization comprising several hundred engineers making a large volume of change requests, we saw an immediate improvement in the quality of change request titles given titles that did not adhere to the standard were prohibited from being merged. We continue to feed any false negatives/positives back into our algorithm to further improve the reliability of the check. We are now in a place where developers can expect a higher standard of change summaries, can succinctly articulate the rationale, and therefore feel a greater sense of purpose for the changes they are making. Reviewers can also more effectively analyze the changes and contribute more meaningful feedback, and stakeholder release notes are focused on the commercial benefits of each change.
We asked a few people to share some thoughts on the title analyzer, and here is what they had to say:
Thanks to the change request title analyzer, our teams now perform streamlined code reviews with comprehensive context upfront. The tooling promotes a positive culture of clarity and collaboration across teams. It's a simple yet impactful addition to our SDLC.
Ankhuri Dubey, Tech Fellow, Managing Director
The change request title analyser ensures that the MR author adds a thoughtful and meaningful title to the change request and provides functional context summarizing the relevance. This helps reviewers as well as other engineers who are looking at the code later, providing a much better context of the reason why a change was implemented.
Sachindra Nath, Tech Fellow
The change request title analyzer encourages our dev team to provide more thoughtful and contextual MR titles. It has been particularly helpful for those of us reviewing code across many disparate projects and at times unfamiliar codebases. A quality MR title that concisely explains its contents and purpose helps us reviewers with context switching and reduces the cognitive load in interpreting the purpose of the code under change.
Mayer Salzer, Tech Fellow
See https://www.gs.com/disclaimer/global_email for important risk disclosures, conflicts of interest, and other terms and conditions relating to this blog and your reliance on information contained in it.
Solutions
Curated Data Security MasterData AnalyticsPlotTool ProPortfolio AnalyticsGS QuantTransaction BankingGS DAP®Liquidity Investing¹ Real-time data can be impacted by planned system maintenance, connectivity or availability issues stemming from related third-party service providers, or other intermittent or unplanned technology issues.
Transaction Banking services are offered by Goldman Sachs Bank USA ("GS Bank") and its affiliates. GS Bank is a New York State chartered bank, a member of the Federal Reserve System and a Member FDIC. For additional information, please see Bank Regulatory Information.
² Source: Goldman Sachs Asset Management, as of March 31, 2025.
Mosaic is a service mark of Goldman Sachs & Co. LLC. This service is made available in the United States by Goldman Sachs & Co. LLC and outside of the United States by Goldman Sachs International, or its local affiliates in accordance with applicable law and regulations. Goldman Sachs International and Goldman Sachs & Co. LLC are the distributors of the Goldman Sachs Funds. Depending upon the jurisdiction in which you are located, transactions in non-Goldman Sachs money market funds are affected by either Goldman Sachs & Co. LLC, a member of FINRA, SIPC and NYSE, or Goldman Sachs International. For additional information contact your Goldman Sachs representative. Goldman Sachs & Co. LLC, Goldman Sachs International, Goldman Sachs Liquidity Solutions, Goldman Sachs Asset Management, L.P., and the Goldman Sachs funds available through Goldman Sachs Liquidity Solutions and other affiliated entities, are under the common control of the Goldman Sachs Group, Inc.
Goldman Sachs & Co. LLC is a registered U.S. broker-dealer and futures commission merchant, and is subject to regulatory capital requirements including those imposed by the SEC, the U.S. Commodity Futures Trading Commission (CFTC), the Chicago Mercantile Exchange, the Financial Industry Regulatory Authority, Inc. and the National Futures Association.
FOR INSTITUTIONAL USE ONLY - NOT FOR USE AND/OR DISTRIBUTION TO RETAIL AND THE GENERAL PUBLIC.
This material is for informational purposes only. It is not an offer or solicitation to buy or sell any securities.
THIS MATERIAL DOES NOT CONSTITUTE AN OFFER OR SOLICITATION IN ANY JURISDICTION WHERE OR TO ANY PERSON TO WHOM IT WOULD BE UNAUTHORIZED OR UNLAWFUL TO DO SO. Prospective investors should inform themselves as to any applicable legal requirements and taxation and exchange control regulations in the countries of their citizenship, residence or domicile which might be relevant. This material is provided for informational purposes only and should not be construed as investment advice or an offer or solicitation to buy or sell securities. This material is not intended to be used as a general guide to investing, or as a source of any specific investment recommendations, and makes no implied or express recommendations concerning the manner in which any client's account should or would be handled, as appropriate investment strategies depend upon the client's investment objectives.
United Kingdom: In the United Kingdom, this material is a financial promotion and has been approved by Goldman Sachs Asset Management International, which is authorized and regulated in the United Kingdom by the Financial Conduct Authority.
European Economic Area (EEA): This marketing communication is disseminated by Goldman Sachs Asset Management B.V., including through its branches ("GSAM BV"). GSAM BV is authorised and regulated by the Dutch Authority for the Financial Markets (Autoriteit Financiële Markten, Vijzelgracht 50, 1017 HS Amsterdam, The Netherlands) as an alternative investment fund manager ("AIFM") as well as a manager of undertakings for collective investment in transferable securities ("UCITS"). Under its licence as an AIFM, the Manager is authorized to provide the investment services of (i) reception and transmission of orders in financial instruments; (ii) portfolio management; and (iii) investment advice. Under its licence as a manager of UCITS, the Manager is authorized to provide the investment services of (i) portfolio management; and (ii) investment advice.
Information about investor rights and collective redress mechanisms are available on www.gsam.com/responsible-investing (section Policies & Governance). Capital is at risk. Any claims arising out of or in connection with the terms and conditions of this disclaimer are governed by Dutch law.
To the extent it relates to custody activities, this financial promotion is disseminated by Goldman Sachs Bank Europe SE ("GSBE"), including through its authorised branches. GSBE is a credit institution incorporated in Germany and, within the Single Supervisory Mechanism established between those Member States of the European Union whose official currency is the Euro, subject to direct prudential supervision by the European Central Bank (Sonnemannstrasse 20, 60314 Frankfurt am Main, Germany) and in other respects supervised by German Federal Financial Supervisory Authority (Bundesanstalt für Finanzdienstleistungsaufsicht, BaFin) (Graurheindorfer Straße 108, 53117 Bonn, Germany; website: www.bafin.de) and Deutsche Bundesbank (Hauptverwaltung Frankfurt, Taunusanlage 5, 60329 Frankfurt am Main, Germany).
Switzerland: For Qualified Investor use only - Not for distribution to general public. This is marketing material. This document is provided to you by Goldman Sachs Bank AG, Zürich. Any future contractual relationships will be entered into with affiliates of Goldman Sachs Bank AG, which are domiciled outside of Switzerland. We would like to remind you that foreign (Non-Swiss) legal and regulatory systems may not provide the same level of protection in relation to client confidentiality and data protection as offered to you by Swiss law.
Asia excluding Japan: Please note that neither Goldman Sachs Asset Management (Hong Kong) Limited ("GSAMHK") or Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H ) ("GSAMS") nor any other entities involved in the Goldman Sachs Asset Management business that provide this material and information maintain any licenses, authorizations or registrations in Asia (other than Japan), except that it conducts businesses (subject to applicable local regulations) in and from the following jurisdictions: Hong Kong, Singapore, India and China. This material has been issued for use in or from Hong Kong by Goldman Sachs Asset Management (Hong Kong) Limited and in or from Singapore by Goldman Sachs Asset Management (Singapore) Pte. Ltd. (Company Number: 201329851H).
Australia: This material is distributed by Goldman Sachs Asset Management Australia Pty Ltd ABN 41 006 099 681, AFSL 228948 (‘GSAMA’) and is intended for viewing only by wholesale clients for the purposes of section 761G of the Corporations Act 2001 (Cth). This document may not be distributed to retail clients in Australia (as that term is defined in the Corporations Act 2001 (Cth)) or to the general public. This document may not be reproduced or distributed to any person without the prior consent of GSAMA. To the extent that this document contains any statement which may be considered to be financial product advice in Australia under the Corporations Act 2001 (Cth), that advice is intended to be given to the intended recipient of this document only, being a wholesale client for the purposes of the Corporations Act 2001 (Cth). Any advice provided in this document is provided by either of the following entities. They are exempt from the requirement to hold an Australian financial services licence under the Corporations Act of Australia and therefore do not hold any Australian Financial Services Licences, and are regulated under their respective laws applicable to their jurisdictions, which differ from Australian laws. Any financial services given to any person by these entities by distributing this document in Australia are provided to such persons pursuant to the respective ASIC Class Orders and ASIC Instrument mentioned below.
- Goldman Sachs Asset Management, LP (GSAMLP), Goldman Sachs & Co. LLC (GSCo), pursuant ASIC Class Order 03/1100; regulated by the US Securities and Exchange Commission under US laws.
- Goldman Sachs Asset Management International (GSAMI), Goldman Sachs International (GSI), pursuant to ASIC Class Order 03/1099; regulated by the Financial Conduct Authority; GSI is also authorized by the Prudential Regulation Authority, and both entities are under UK laws.
- Goldman Sachs Asset Management (Singapore) Pte. Ltd. (GSAMS), pursuant to ASIC Class Order 03/1102; regulated by the Monetary Authority of Singapore under Singaporean laws
- Goldman Sachs Asset Management (Hong Kong) Limited (GSAMHK), pursuant to ASIC Class Order 03/1103 and Goldman Sachs (Asia) LLC (GSALLC), pursuant to ASIC Instrument 04/0250; regulated by the Securities and Futures Commission of Hong Kong under Hong Kong laws
No offer to acquire any interest in a fund or a financial product is being made to you in this document. If the interests or financial products do become available in the future, the offer may be arranged by GSAMA in accordance with section 911A(2)(b) of the Corporations Act. GSAMA holds Australian Financial Services Licence No. 228948. Any offer will only be made in circumstances where disclosure is not required under Part 6D.2 of the Corporations Act or a product disclosure statement is not required to be given under Part 7.9 of the Corporations Act (as relevant).
FOR DISTRIBUTION ONLY TO FINANCIAL INSTITUTIONS, FINANCIAL SERVICES LICENSEES AND THEIR ADVISERS. NOT FOR VIEWING BY RETAIL CLIENTS OR MEMBERS OF THE GENERAL PUBLIC
Canada: This presentation has been communicated in Canada by GSAM LP, which is registered as a portfolio manager under securities legislation in all provinces of Canada and as a commodity trading manager under the commodity futures legislation of Ontario and as a derivatives adviser under the derivatives legislation of Quebec. GSAM LP is not registered to provide investment advisory or portfolio management services in respect of exchange-traded futures or options contracts in Manitoba and is not offering to provide such investment advisory or portfolio management services in Manitoba by delivery of this material.
Japan: This material has been issued or approved in Japan for the use of professional investors defined in Article 2 paragraph (31) of the Financial Instruments and Exchange Law ("FIEL"). Also, any description regarding investment strategies on or funds as collective investment scheme under Article 2 paragraph (2) item 5 or item 6 of FIEL has been approved only for Qualified Institutional Investors defined in Article 10 of Cabinet Office Ordinance of Definitions under Article 2 of FIEL.
Interest Rate Benchmark Transition Risks: This transaction may require payments or calculations to be made by reference to a benchmark rate ("Benchmark"), which will likely soon stop being published and be replaced by an alternative rate, or will be subject to substantial reform. These changes could have unpredictable and material consequences to the value, price, cost and/or performance of this transaction in the future and create material economic mismatches if you are using this transaction for hedging or similar purposes. Goldman Sachs may also have rights to exercise discretion to determine a replacement rate for the Benchmark for this transaction, including any price or other adjustments to account for differences between the replacement rate and the Benchmark, and the replacement rate and any adjustments we select may be inconsistent with, or contrary to, your interests or positions. Other material risks related to Benchmark reform can be found at https://www.gs.com/interest-rate-benchmark-transition-notice. Goldman Sachs cannot provide any assurances as to the materialization, consequences, or likely costs or expenses associated with any of the changes or risks arising from Benchmark reform, though they may be material. You are encouraged to seek independent legal, financial, tax, accounting, regulatory, or other appropriate advice on how changes to the Benchmark could impact this transaction.
Confidentiality: No part of this material may, without GSAM's prior written consent, be (i) copied, photocopied or duplicated in any form, by any means, or (ii) distributed to any person that is not an employee, officer, director, or authorized agent of the recipient.
GSAM Services Private Limited (formerly Goldman Sachs Asset Management (India) Private Limited) acts as the Investment Advisor, providing non-binding non-discretionary investment advice to dedicated offshore mandates, involving Indian and overseas securities, managed by GSAM entities based outside India. Members of the India team do not participate in the investment decision making process.